
TLDR: How and why I made the Paper of The Day Chrome app
I created a Chrome app called Paper of The Day. This app helps you find trending research papers from different academic disciplines and shows you one each time you open a new tab in Chrome. I did this to help me stay notified of the latest trends with minimal effort.
Introduction
I have a continuous fear of not staying informed. Not in the sense of the news or what’s trending on twitter, but rather geeky things like ‘What are the latest academic trends?’. My reasoning is selfish — I want to know if there are ideas out there I could leverage to create cool new things. This project is about trying to hack my life to achieve more of those ‘serendipitous’ breakthrough moments.
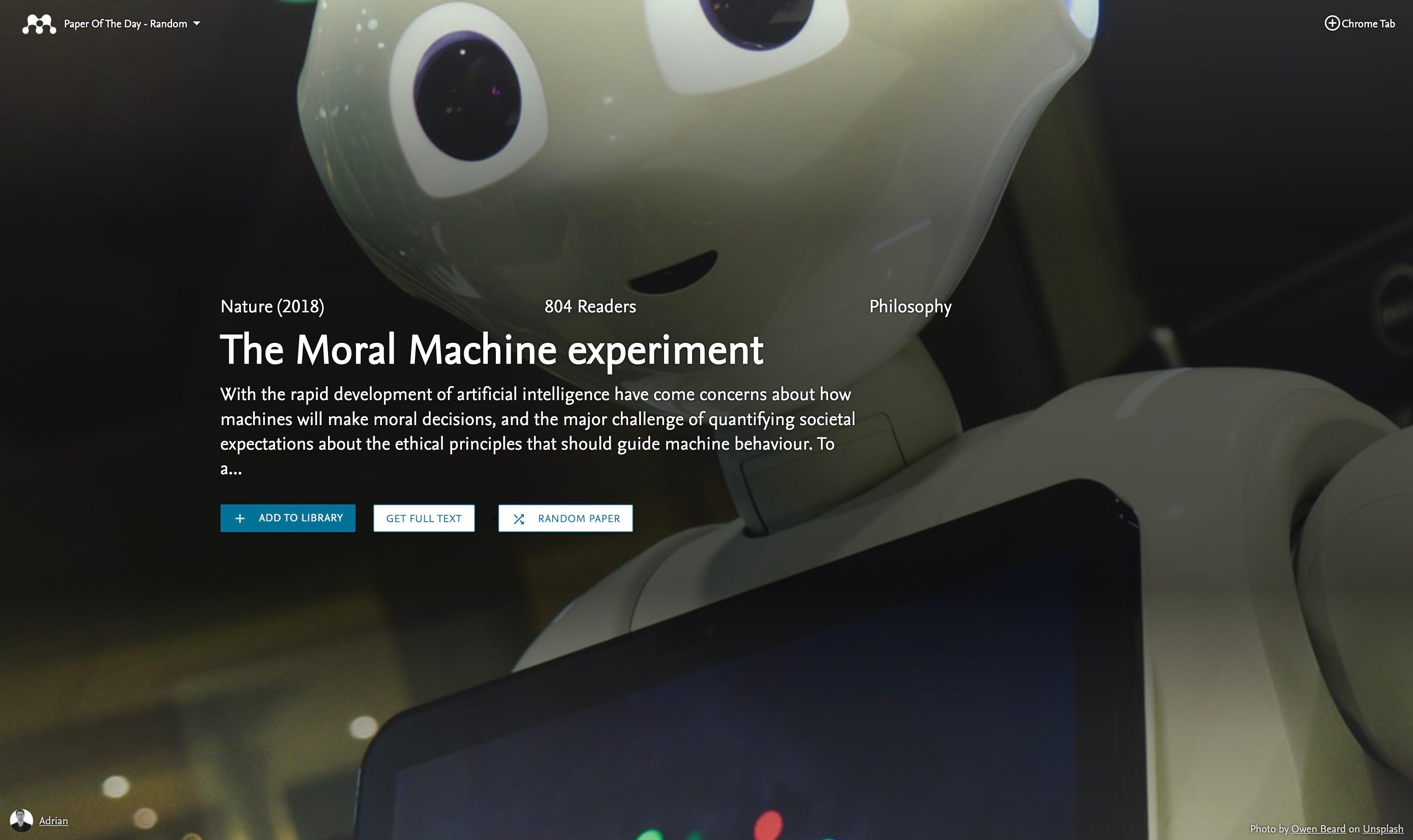
If I were to ask for example ‘What are the top trending papers in Computer Science are right now’ — how would you find out? Google Search? Date of publication? The number of citations? It’s an interesting question.
One of the problems is that I’m a bit lazy. When am I going to sit down and look at a list of trending papers every day? I want an easy to consume, prepackaged way to discover them.
Inspiration
Two tools acted as a source of inspiration for this project.
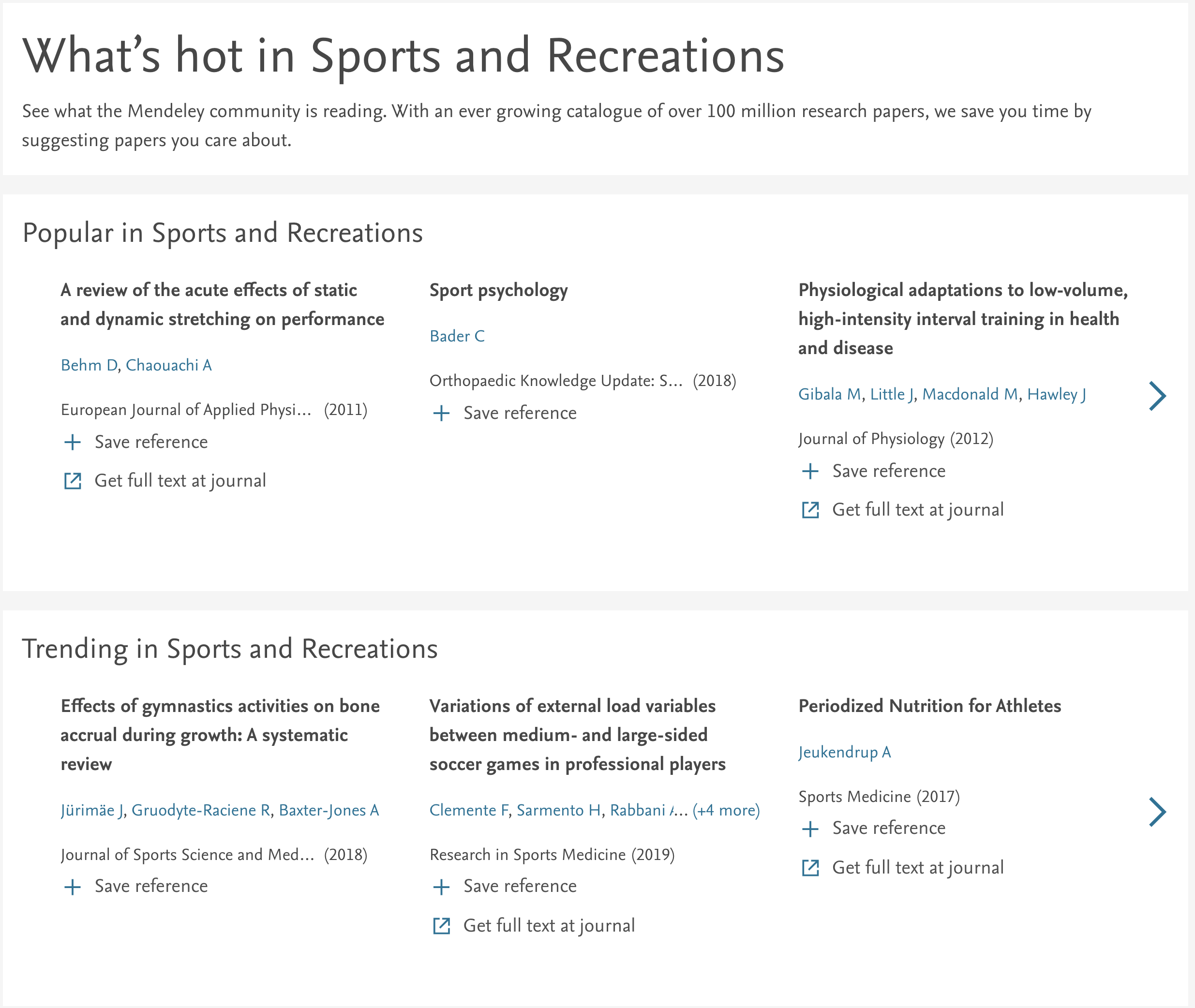
The first was the Mendeley recommender. Mendeley is primarily a reference manager which helps academics cite papers. But it also happens to have an API that helps find ‘popular’ or ‘trending’ articles for a range of academic disciplines. It achieves this by examining broad academic reading trends within the Mendeley network. The feature is pretty impressive, but I don’t think it gets the attention it deserves.
](https://cdn-images-1.medium.com/max/NaN/1*TB1WnJm5edNrSWLBJw0ZRg.jpeg)
The second point of inspiration is a productivity plugin called ‘Momentum’. Every time you open a new tab in chrome Momentum will show you a motivational message and even a todo list, prompting you to stay focused. I feel like I could hack this idea — show a new random trending academic paper with each new tab opened! Now we are getting somewhere.
Technical Problems
Let’s start by setting some expectations — this is not meant to be a serious academic research tool. It’s more like a way to introduce serendipitous discovery into my day. Perhaps I will come across ideas, concepts or papers I would otherwise not encountered.
The significant part is that the Mendeley community has somewhat vetted these papers, so I can assume a decent level of quality for anything selected. The problem is, it’s unlikely the content will be especially intriguing to me, so an open mindset is required when browsing these articles.
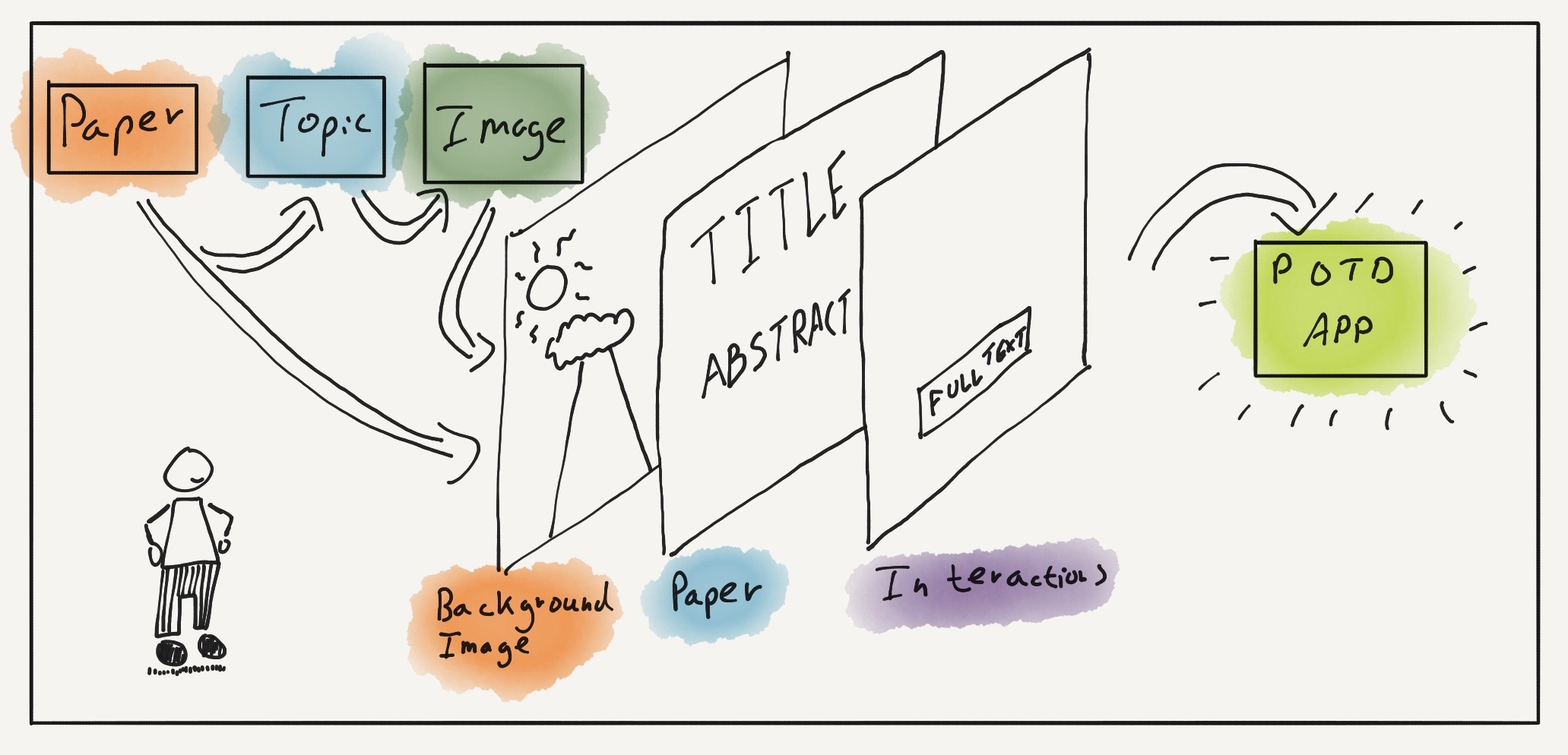
Because this app is going to take over my screen every time I open a tab, I need a charming visual which quickly conveys the content of the selected paper. Unfortunately, academic journals are not known to have excellent graphic design covers. Similarly, the images/diagrams within an article are unlikely to be aesthetically pleasing enough to leverage as a backdrop image.
Excluding the issue of trying to find an automated way of finding an image, a whole bunch of other intriguing questions emerged like: What image do you choose to visualise something like ‘quantum theory’ or ‘asset pricing implications’? A royalty-free image service that could take keywords and convert them to images looked like my best bet here.
Solution
So, at this point in the story, I’m pretty convinced on using the Mendeley recommender API to pick the papers — so that’s covered. The API gives me a bunch of information about each paper like title, abstract, DOI, reader count and links to the article page/PDF. That’s enough to get started.
Being heavily inspired by Momentum and cover designs from the British Medical Journal (BMJ), I set to work using Figma to sketch out some ideas of how the app could look.
I’ve always been impressed by the effort graphic designers at the BMJ put into their cover illustrations.
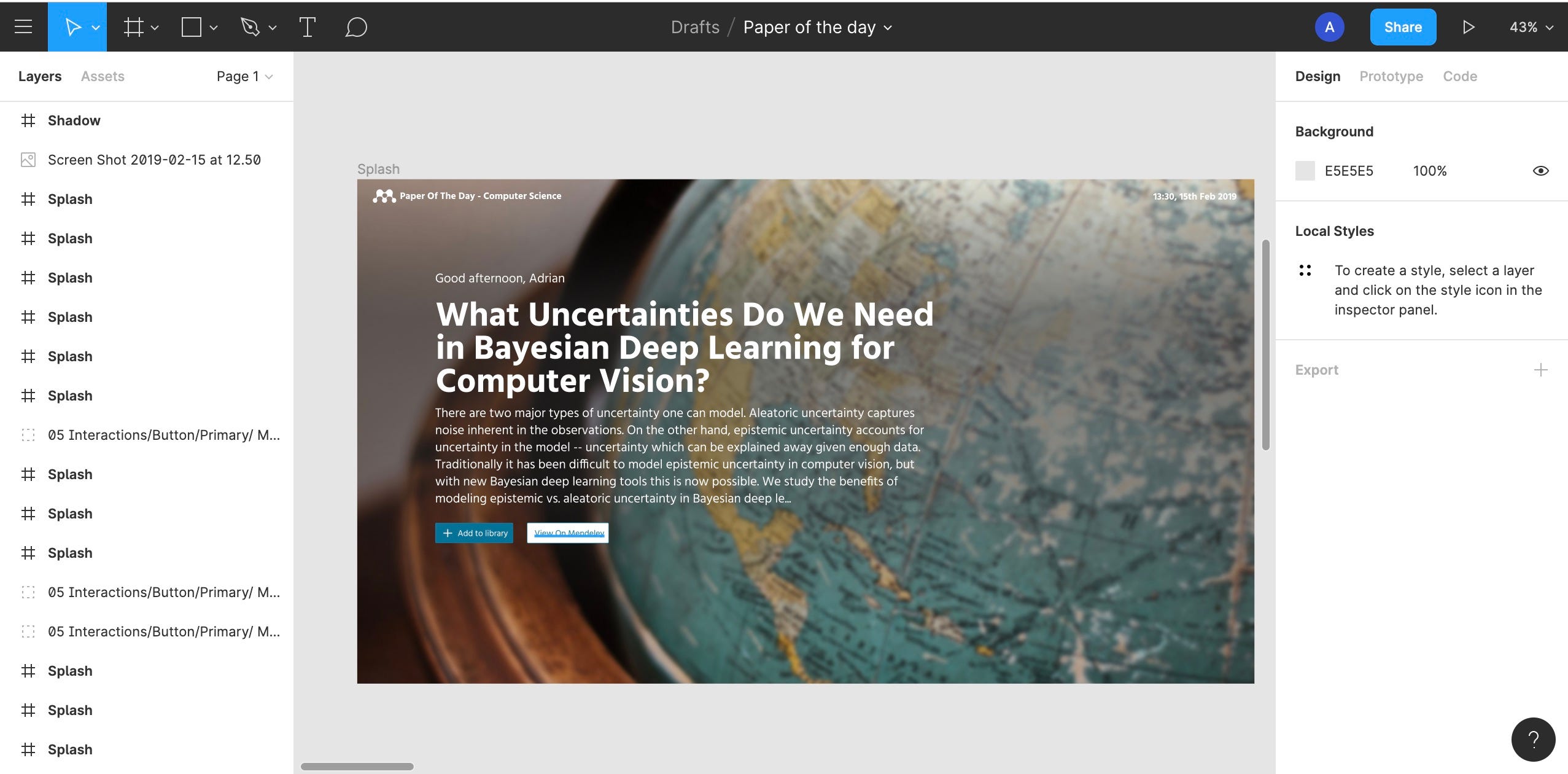
Using google image search and Unsplash, I quickly picked out some background images for some random papers then overlaid them with text and some buttons. Done — now for some user testing.
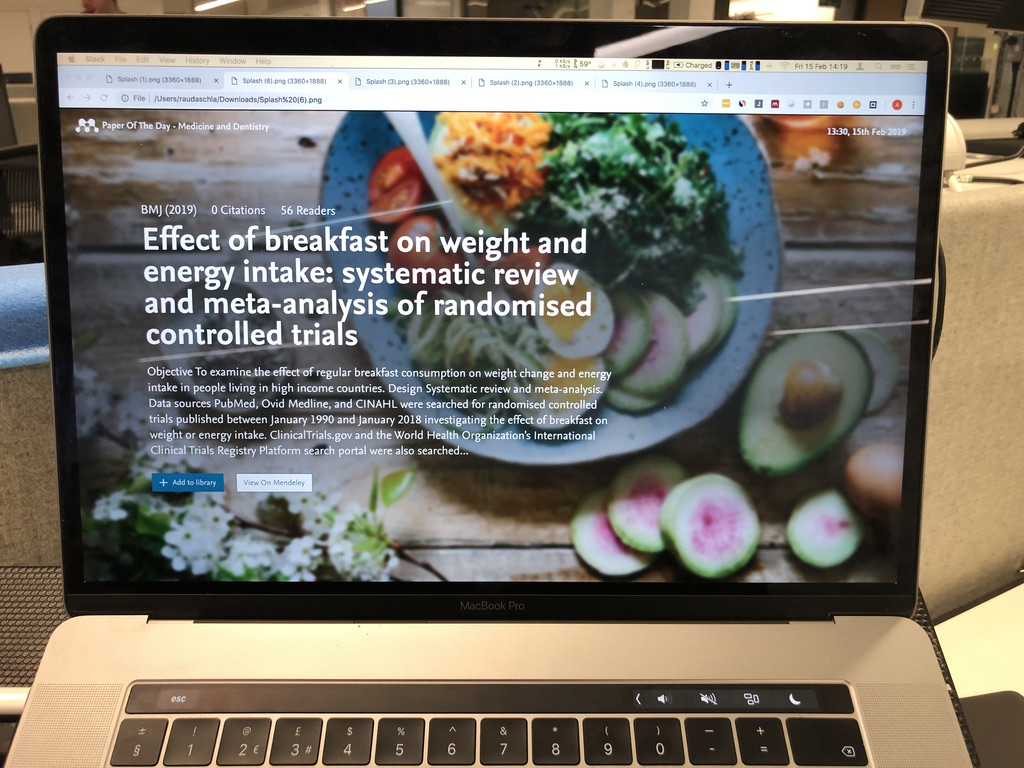
After loading the exported jpg’s into Chrome, I wondered over to unsuspecting colleagues and friends ready to show off my new creation. A few approving nods later and I felt confident to move onto the next stage: coding. The question remained though, how was I going to automate the selection of those background images?
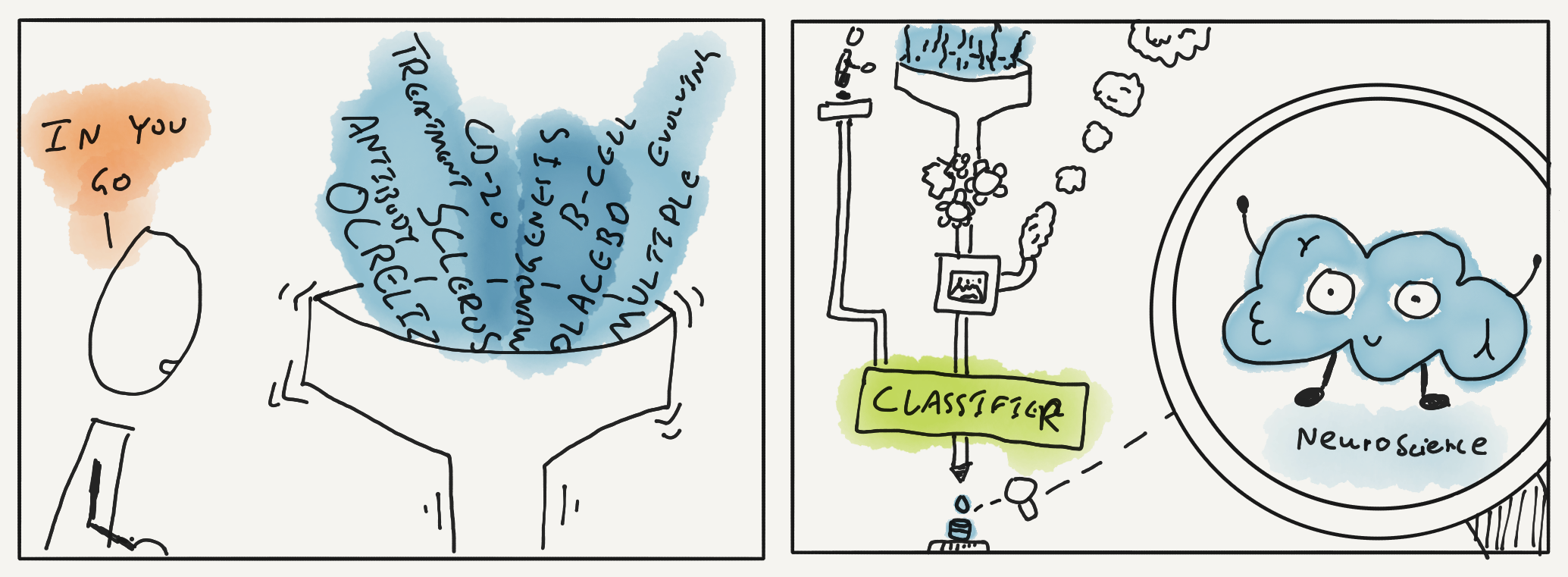
One way to solve this is to take a bunch of text from different academic articles like titles and abstracts, then use it to train something called a ‘topic model’. The theory is that after a model is trained, I can show it something like the abstract of a paper it has not seen before and it will try to guess the topic it belongs to.
You can achieve this with some pretty amazing machine learning tools like LDA (Latent Dirichlet Allocation) or bag of words. I found this tutorial if you are interested in reading up on this stuff yourself.
Thankfully though, it turned out there was already a team in my company (Elsevier) building such a topic model classifier (specifically for scientific topics). All I needed was some free text, like a title or abstract, and this service would try to classify it based on a scientific hierarchy (called Omniscience) — perfect.
Implementing the service
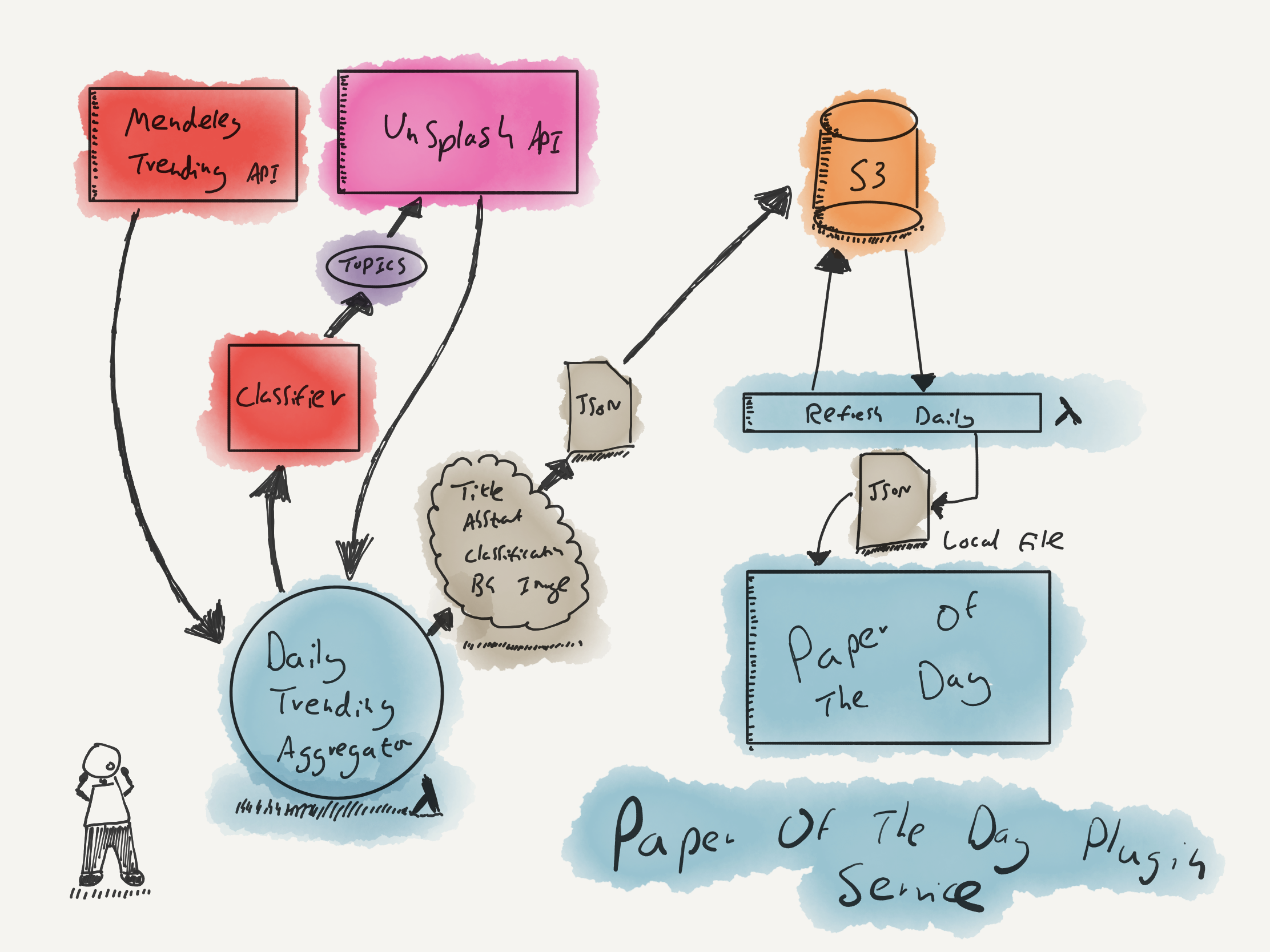
I think I have all the components we need now.
For each paper selected by the trending API, I can pass that papers title and abstract to the topic classifier, get a topic back, give that keyword to an image API, get an image URL back and store the result. This job will run once a day on a Lambda for a range of different scientific disciplines, aggregate the results and save the output as a JSON file on an S3 bucket.
Once a day, when a user opens the Chrome app, it checks if this ‘papers’ file has updated. If it hasn’t, it will call our API and store the trending papers file locally (minimising the number of requests required). It’s simple but should work.
For the Frontend stack, I’m not doing anything fancy: just HTML, vanilla javascript and a CSS framework called Materialise. I could have used a more sophisticated framework, but I want to keep things as lightweight as possible. All this service needs to do now is check for new papers, download them, display them and repeat.

But there is a little time for some bells and whistles: it would be cool if you could also choose your discipline of interest, so I added a dropdown for that.
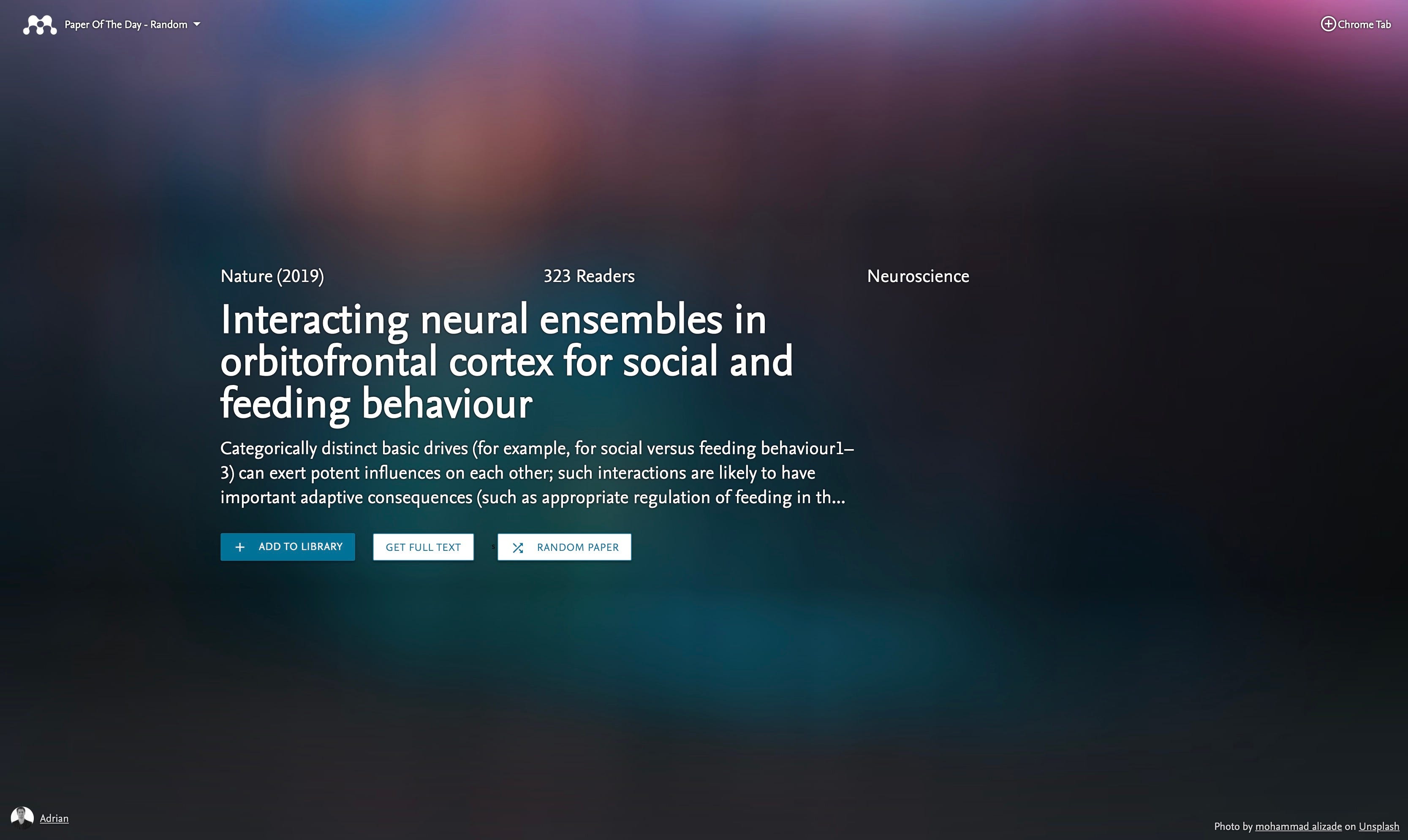
And voila! A new random trending academic paper for each new browser tab. I’m feeling more worldly and productive already.
Impact
Its been about six months now since I launched the app on the chrome store and overall, I’m pretty happy with the results.

At the time of writing, there are roughly around 600 weekly active users (hopefully nothing breaks), and a few nice reviews. Somebody even made a YouTube video (shout out below).
For me, I’m just happy some people seem to enjoy it. The learning experience of building this was fun. I event took the opportunity over the last few months to add some new features like ‘Sign in with Mendeley’, ‘Add to Library’ and ‘Share’.
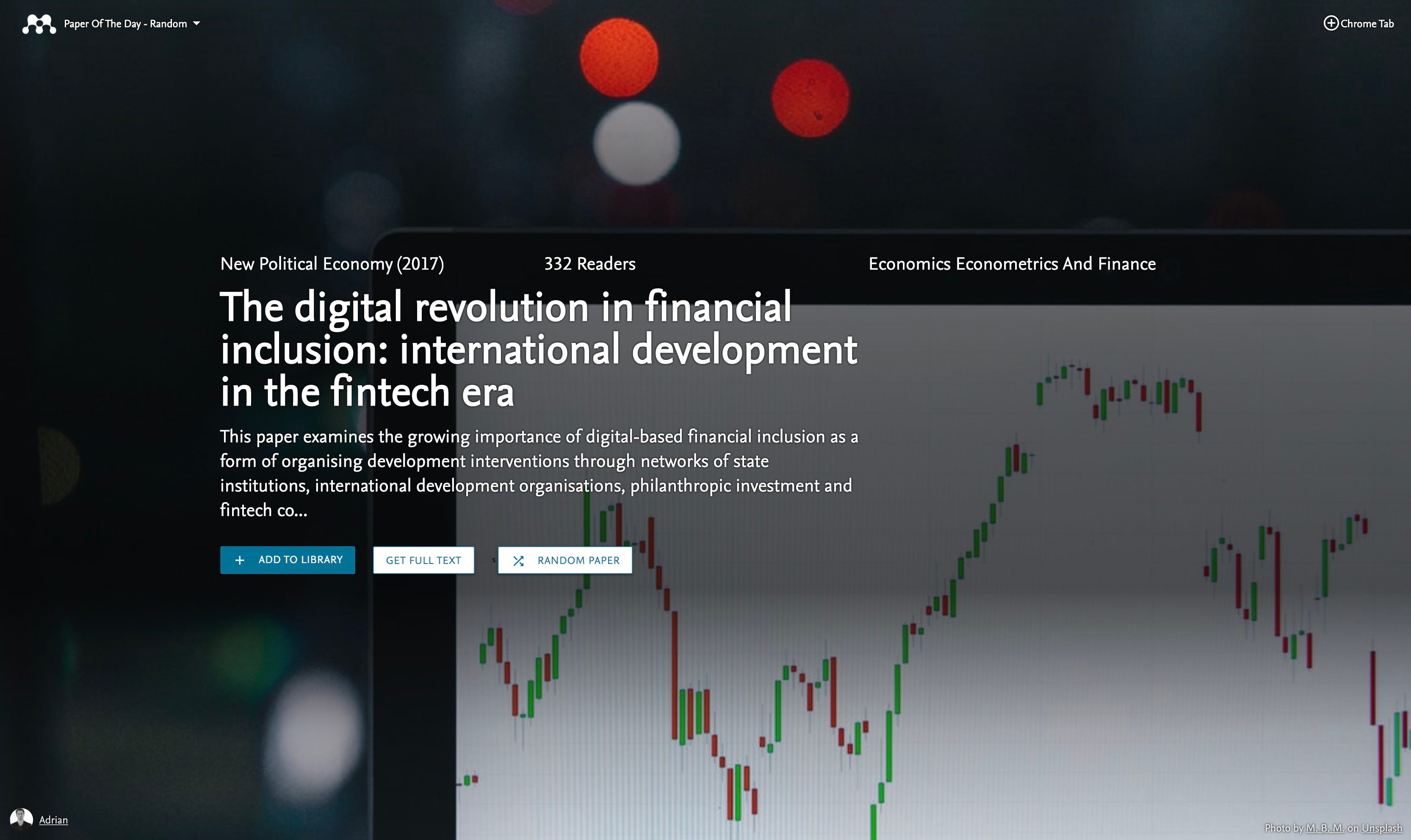
I also spent a bit of time trying to optimise the image selection for different articles. Eventually, I settled on something between an automated and a pre-defined image selection system based on keywords.
At the start, there were a few borderline offensive and product placement images which were not appropriate, but now those get filtered out automatically.
Future
Getting the image matching more accurate would be cool, but I find it hits its mark around 80% of the time. Any topic which is too weird to pair with an image automatically gets a lovely ‘abstract’ design.
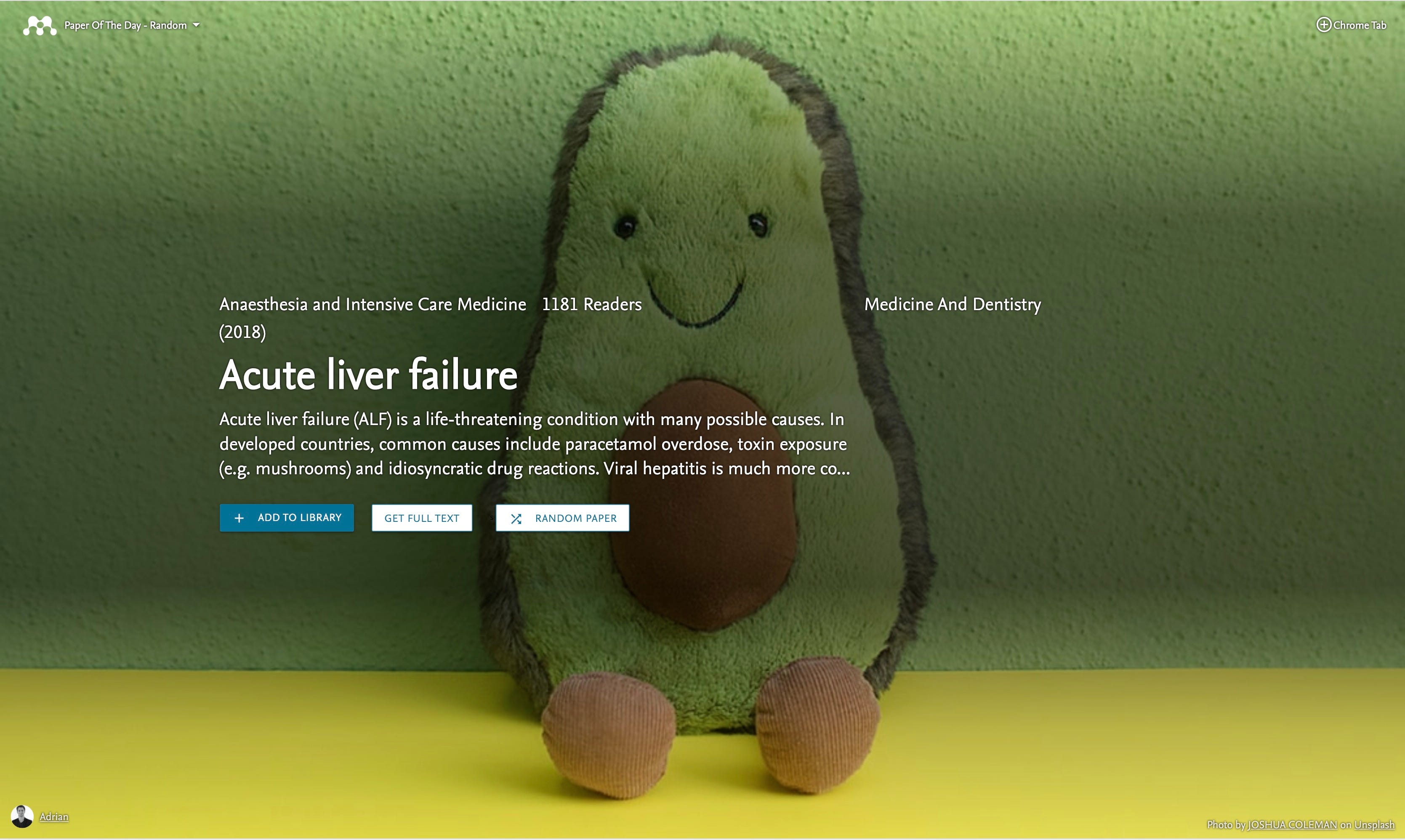
Ideally, I want to make this app more personal for each user. For example, if you link your Mendeley Library, I want to show you recommended papers based on what you have recently been reading. That could be cool.
This project has helped open my eyes to new ways of discovering academic content. The Mendeley reader metric, for example, looks like it could be an exciting way to predict future relevant academic papers even before they are cited. Maybe I will find a use for that next.
I hope you enjoyed reading this. If you have any questions or ideas for new app features, please feel free to drop a line in the comments below.
Full disclosure: I’m a product manager working at Mendeley. The Paper of The Day app is not affiliated with Mendeley in any way and is just a personal experiment. All thoughts expressed here are my own.