
Scopus AI
The prototype I built that became a generative AI research platform used by millions of researchers worldwide.

Project Overview
Scopus AI grew out of two converging threads: years of investment in vector search at Elsevier, and my own obsession with personal knowledge management tools like Obsidian. When GPT-3's API became available in mid-2020, I combined the two into prototypes that could retrieve relevant research and use it to generate grounded answers, what we'd later call RAG.
The result was the original Scopus AI prototype, a system that combined generative AI with Scopus's database of over 90 million research records. Instead of keyword matching, it understood what a researcher was actually asking, retrieved relevant evidence, and synthesised a grounded answer with proper citations. Working alongside Henry Cleland and Erik Schwartz, this prototype became the foundation that enabled a dedicated team to build the Scopus AI product that millions of researchers use today.
Along the way, I developed RAG-Fusion, a retrieval-augmented generation technique that has since been adopted by the broader AI community, with over 800 stars on GitHub.
Why Build This
After rebuilding search at Mendeley, I had a decent understanding of how retrieval systems worked: Elasticsearch, boolean queries, lexical matching. I also had a front-row seat to a core limitation. Researchers didn't always know the right keywords. They had questions, not query strings, and the tools we gave them were designed for the latter.
Around the same time, I'd become a bit obsessed with the "second brain" movement: tools like Obsidian for building personal knowledge bases out of markdown files, the idea that you could capture everything you read and connect it in ways your own memory couldn't. I was using it in my personal life, and it got me thinking about what would happen if you combined that kind of knowledge management with large language models. What if a system could not only store and retrieve information, but actually reason over it?
Meanwhile, at work, we'd already been investing in vector search capabilities well before 2020. Vectorisation of content was becoming genuinely feasible at production scale, which meant natural language search was no longer a research paper fantasy. During the pandemic, I started experimenting with these techniques in my own knowledge management workflow, and the results were promising enough that I couldn't stop thinking about what they could do for researchers at Scopus's scale.
Then GPT-3's API became available in mid-2020, and things really started cooking. I built prototypes that combined vector search with generative AI, retrieving relevant information and using it to inform how a response was written. At the time, this didn't have a name. Now we call it RAG: retrieval-augmented generation. But the instinct was simpler than the acronym. Instead of returning a list of documents and leaving the researcher to figure out what was relevant, what if the system could read the question, understand intent, find the right papers, and synthesise a useful answer with proper citations?
The problem was real and personal. As a former doctor, I knew what it felt like to need specific evidence under time pressure. And at Elsevier, I could see millions of researchers hitting the same wall every day: sifting through results, unsure whether they had found what they needed or simply what the algorithm happened to surface.
Building the Prototype
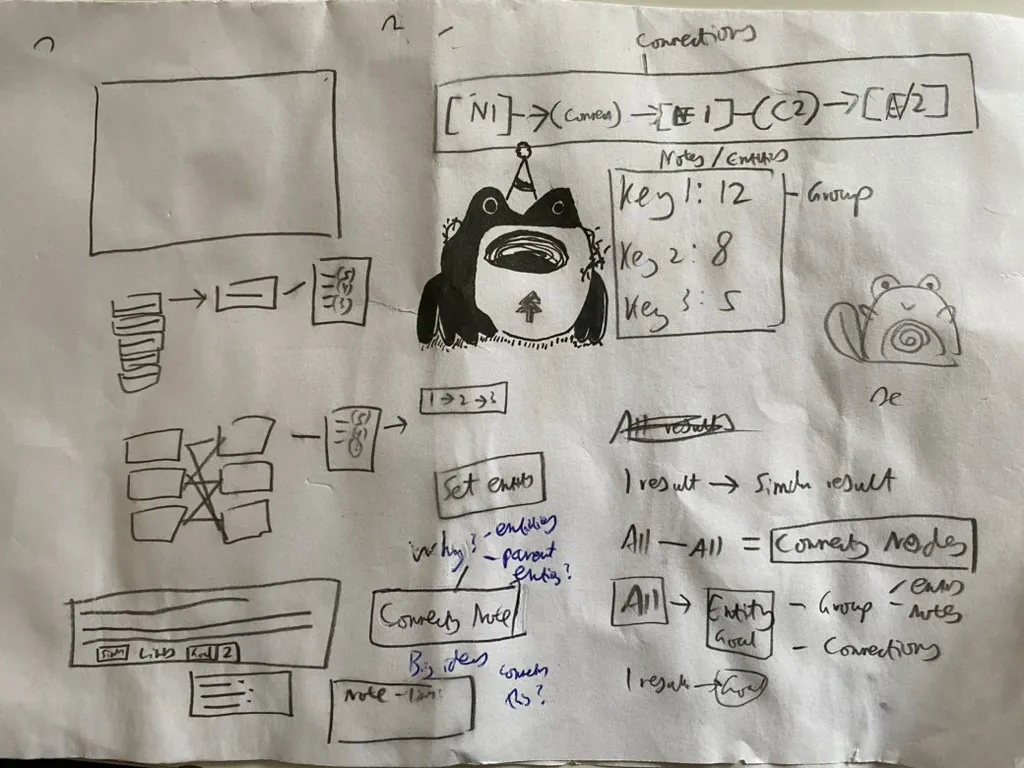
It started on paper. Before writing any code, I was sketching out how nodes and connections might work, how you'd link entities to groups, how search results could feed into something more structured. Quite a lot of doodling alongside some questionable cartoon characters.
2021: Working out how nodes, entities, and connections might fit together
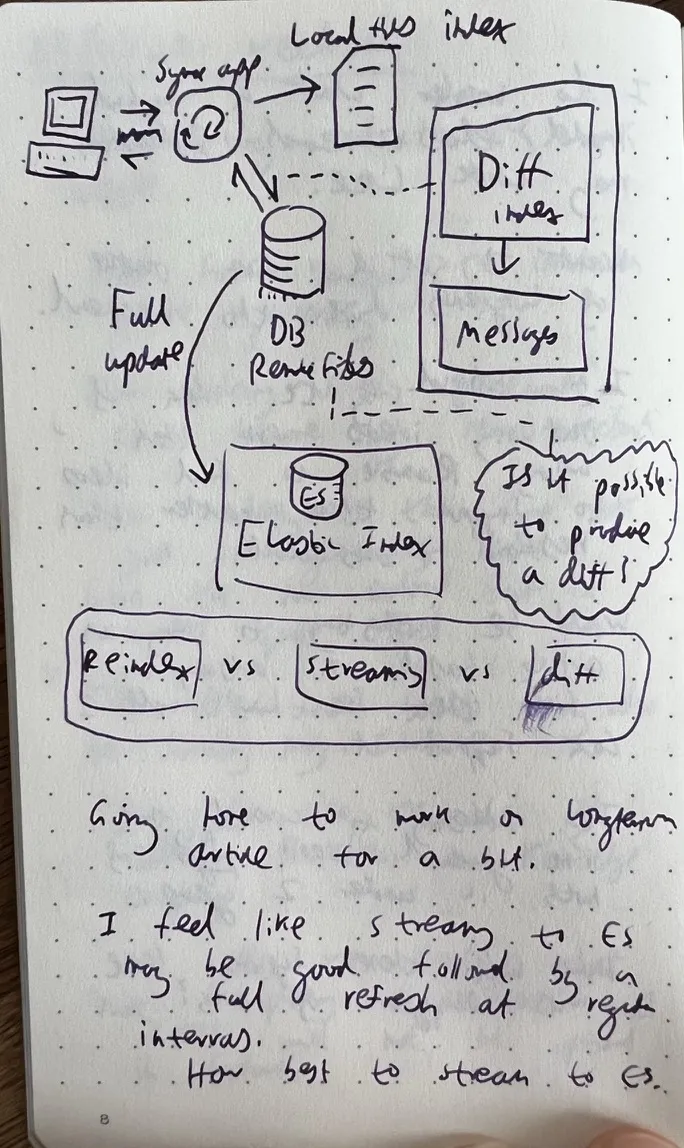
Jan 2022: Figuring out how to keep a vector index in sync with Elasticsearch
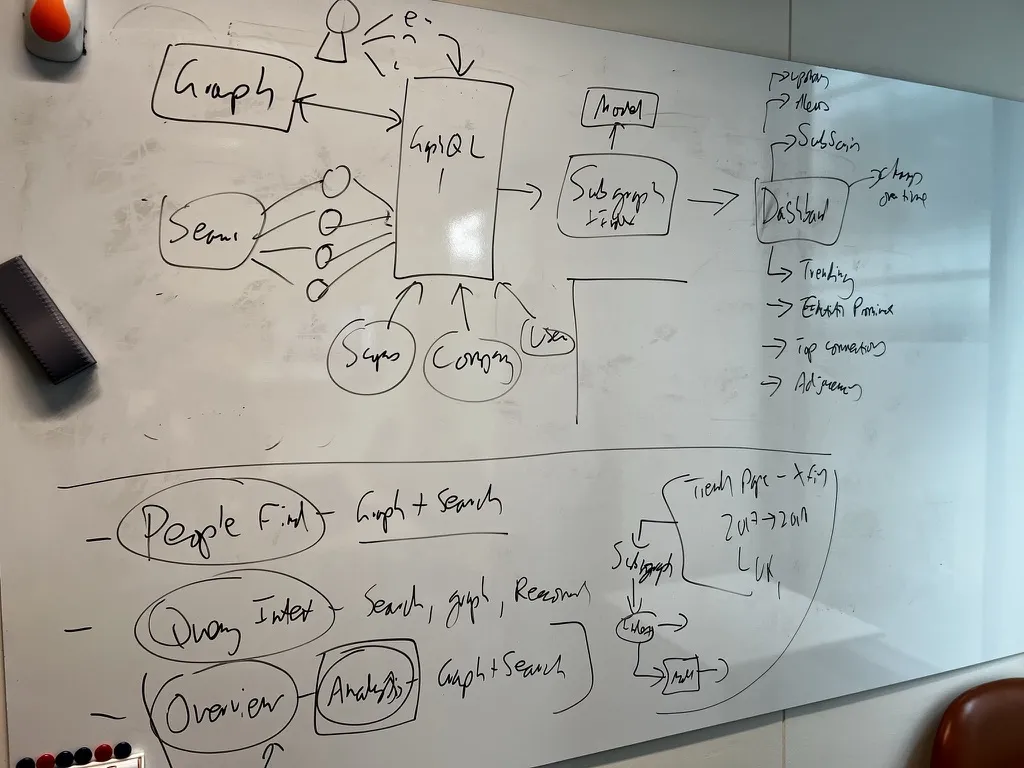
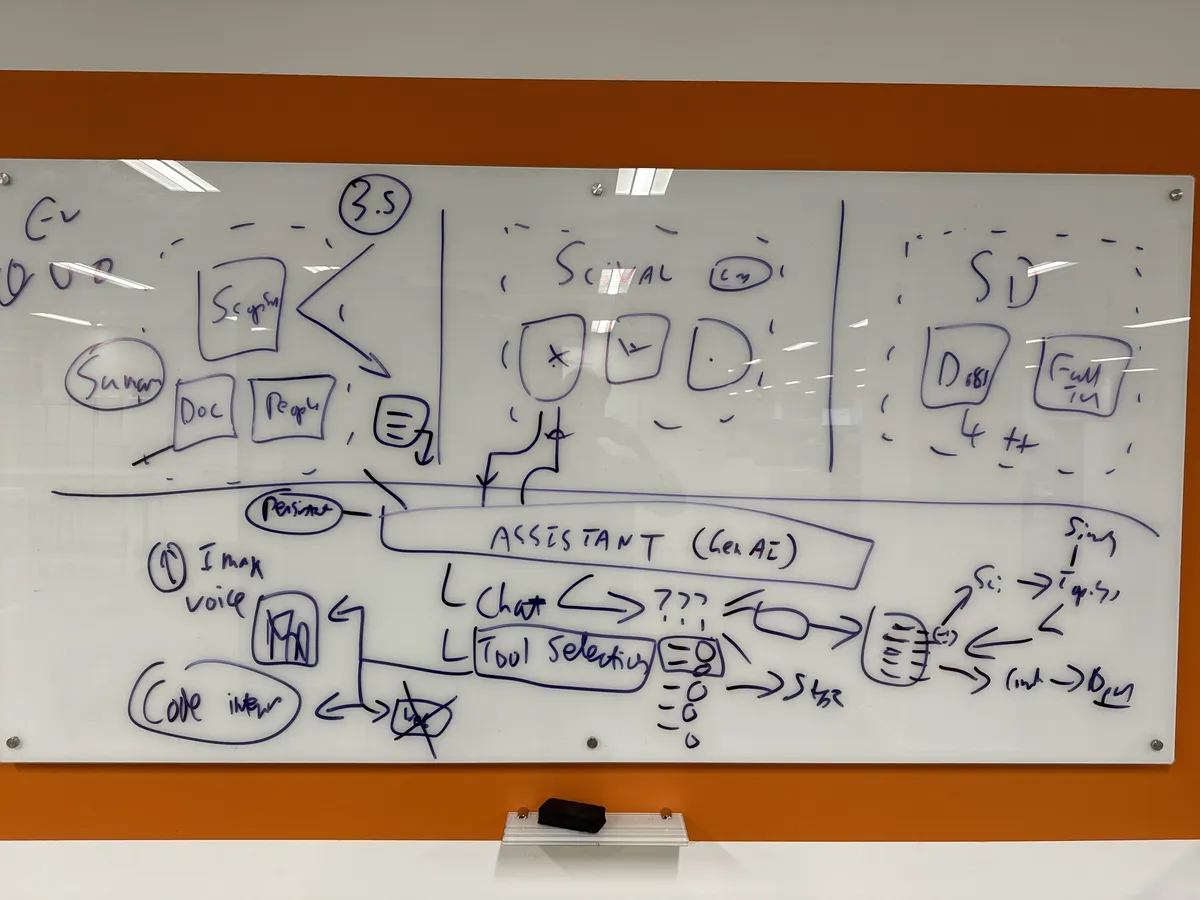
We called the project Sebright. The early whiteboards were a mix of ambition and uncertainty: how to connect Graph, Scopus, and ScienceDirect through a single query layer, how to handle People Find alongside document search, whether GraphQL was the right abstraction. The usual product questions, but with the added complexity of trying to make AI behave responsibly over academic literature.
April 2022: The first architecture sketch for the prototype
Mapping every step of the RAG pipeline over coffee

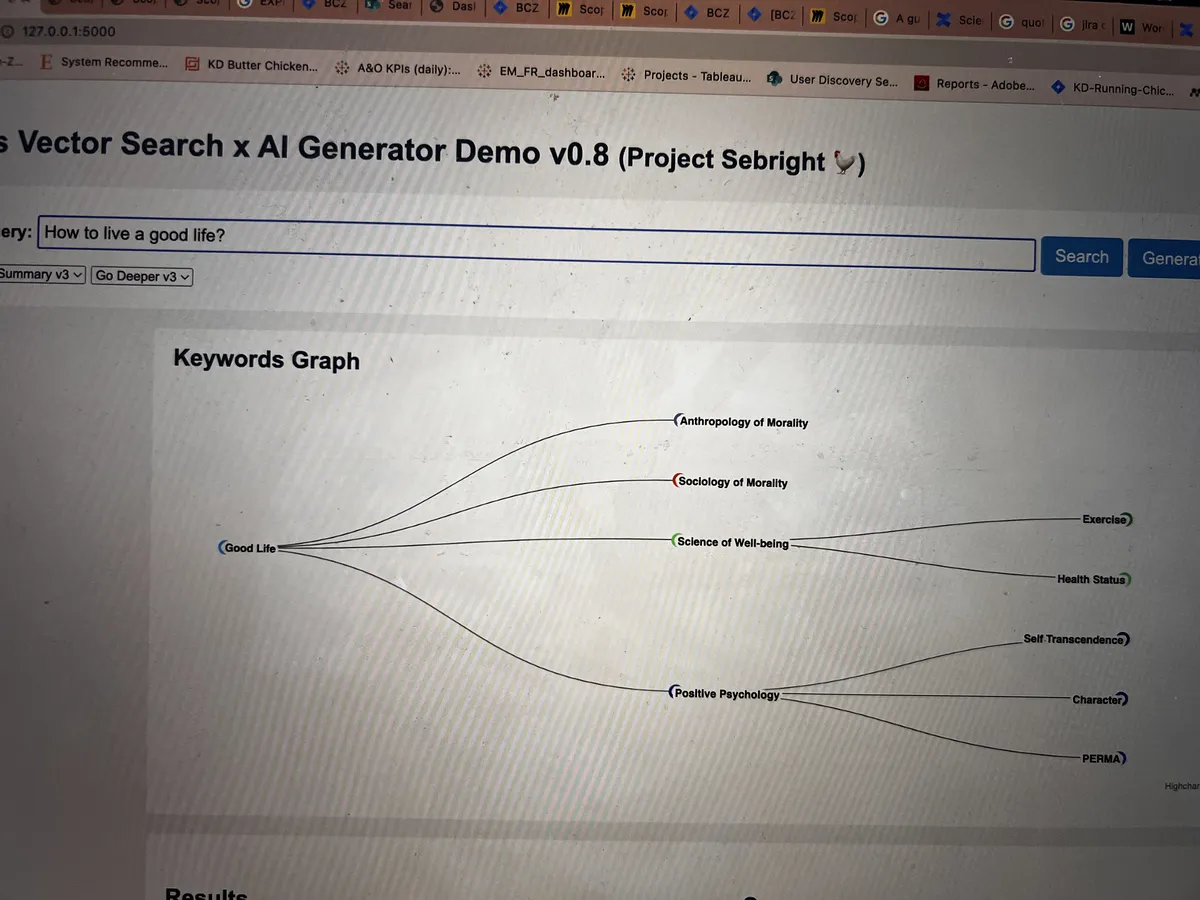
The early versions were rough, but they proved the concept worked: ask a natural language question, get a grounded answer with citations and a keyword graph showing how concepts connected across the literature.
The first time it worked: a question in, a knowledge graph out
Getting closer: grounded summaries with real citations
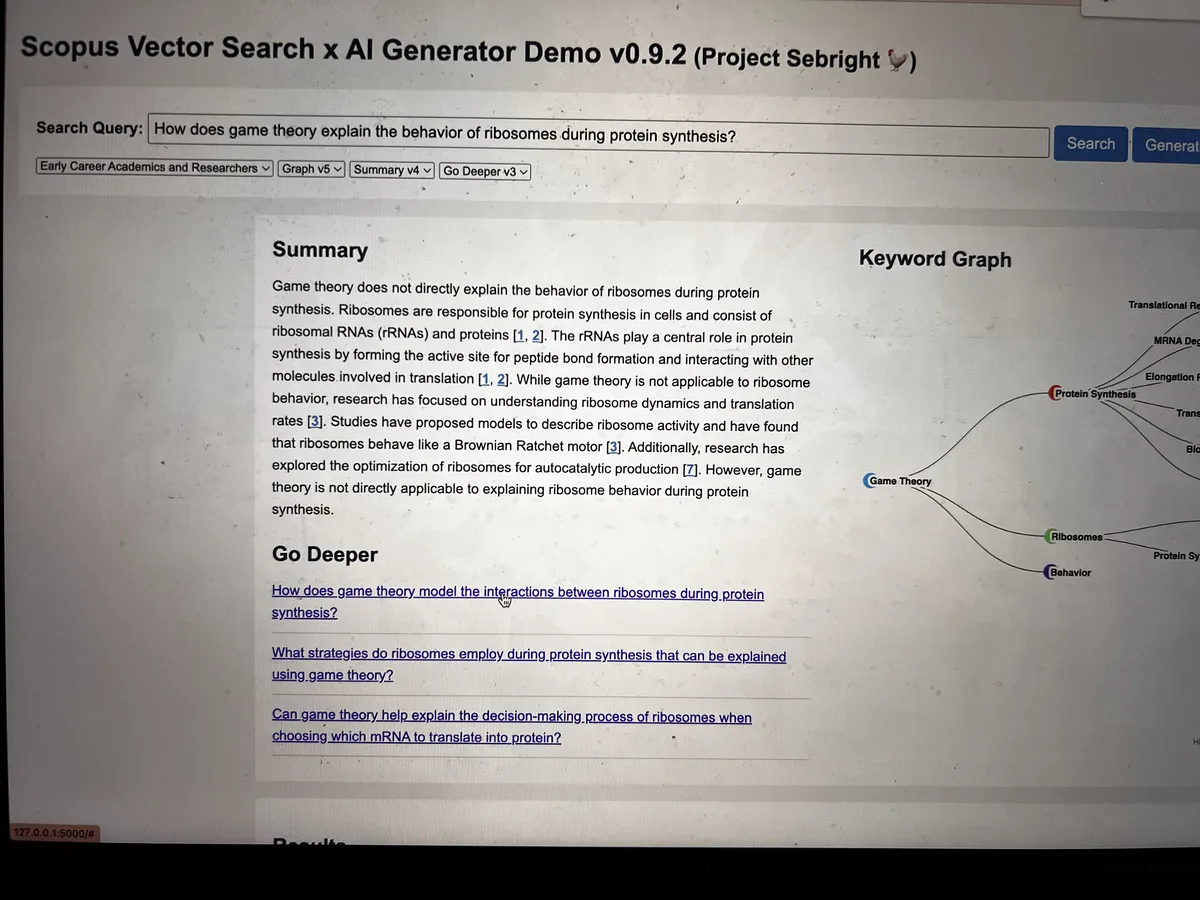
Between versions, there were a lot of whiteboards. We iterated on embedding search, automated ingestion, summary generation, and prompt engineering. The sprint boards were a mix of serious infrastructure work and jokes (a recurring item labelled "Butter Chicken" may or may not have been a legitimate sprint goal).
Wireframing the next version with Henry

The sprint board that always had "Butter Chicken" on it

Eventually the pieces came together. The system could take a research question, generate multiple query perspectives, search across Scopus's 90 million records using vector embeddings, and synthesise a grounded answer. We knew we had something worth showing to the wider organisation.
Scaling up: planning the AI assistant architecture across Scopus, SciVal, and ScienceDirect
How It Works
Query Understanding
Traditional academic search expects researchers to know the right terms. Scopus AI starts by understanding what they actually want to know.
- •Natural language questions instead of boolean query strings
- •Semantic understanding of research concepts and their relationships
- •RAG-Fusion generates multiple query perspectives to capture different facets of the question
Evidence Retrieval
The prototype searched across Scopus's 90M+ research records using vector embeddings rather than keyword matching, surfacing papers that were conceptually relevant even when the terminology differed.
- •Semantic vector search over tens of millions of abstracts and full-text articles
- •Reciprocal Rank Fusion to combine results from multiple query perspectives
- •Cross-disciplinary discovery: finding relevant work across fields the researcher might not have considered
Grounded Synthesis
Rather than just listing papers, the system reads the retrieved evidence and generates a synthesis: a coherent answer grounded in the actual research, with every claim linked back to its source.
- •Every statement backed by citations to specific papers in the Scopus database
- •Transparent reasoning: researchers can verify claims against the original sources
- •Designed around academic rigour: no hallucinated references, no unsupported claims
RAG-Fusion
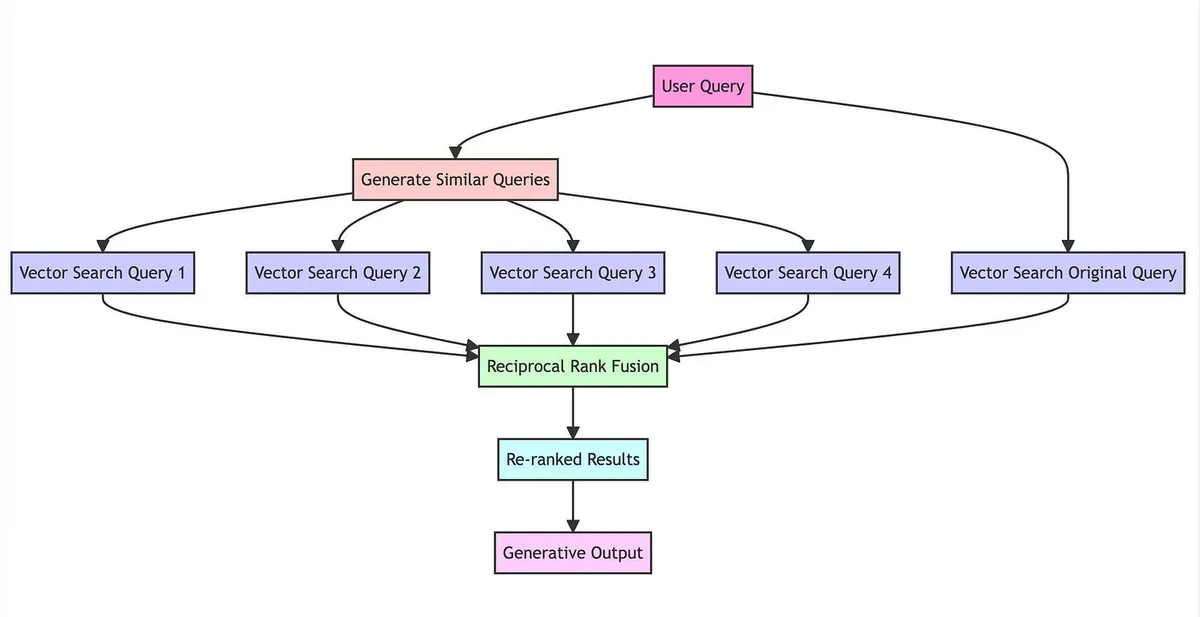
One of the techniques I developed during this work was RAG-Fusion. The core insight was simple: a single query often misses relevant results because it only captures one way of asking the question. RAG-Fusion uses a language model to generate multiple query perspectives from the original question, retrieves results for each, and then fuses the rankings using Reciprocal Rank Fusion.
The RAG-Fusion pipeline: one question in, multiple perspectives out
I wrote it up in a blog post titled "Forget RAG, the Future is RAG-Fusion" (a title I'll admit was designed to be a bit provocative), and open-sourced the implementation. It struck a nerve. The GitHub repository has accumulated over 800 stars, and the approach has been adopted by teams building RAG systems across the industry.
The technique is now part of a patent application, alongside other retrieval innovations developed during the Scopus AI work.
Impact
Millions of Researchers
The prototype became the foundation for Scopus AI, now used by millions of researchers across institutions worldwide.
Open Source Adoption
RAG-Fusion has over 800 GitHub stars and has been adopted by teams building retrieval systems across the AI industry.
Multiple Patents
The retrieval and generation techniques developed during this work are covered by multiple patent applications.
Paradigm Shift
Helped drive Elsevier's transition from keyword matching to semantic understanding across five research products.
Demoing Scopus AI to a packed crowd at the RELX AI London conference

External validation: VP Data Science announces the launch
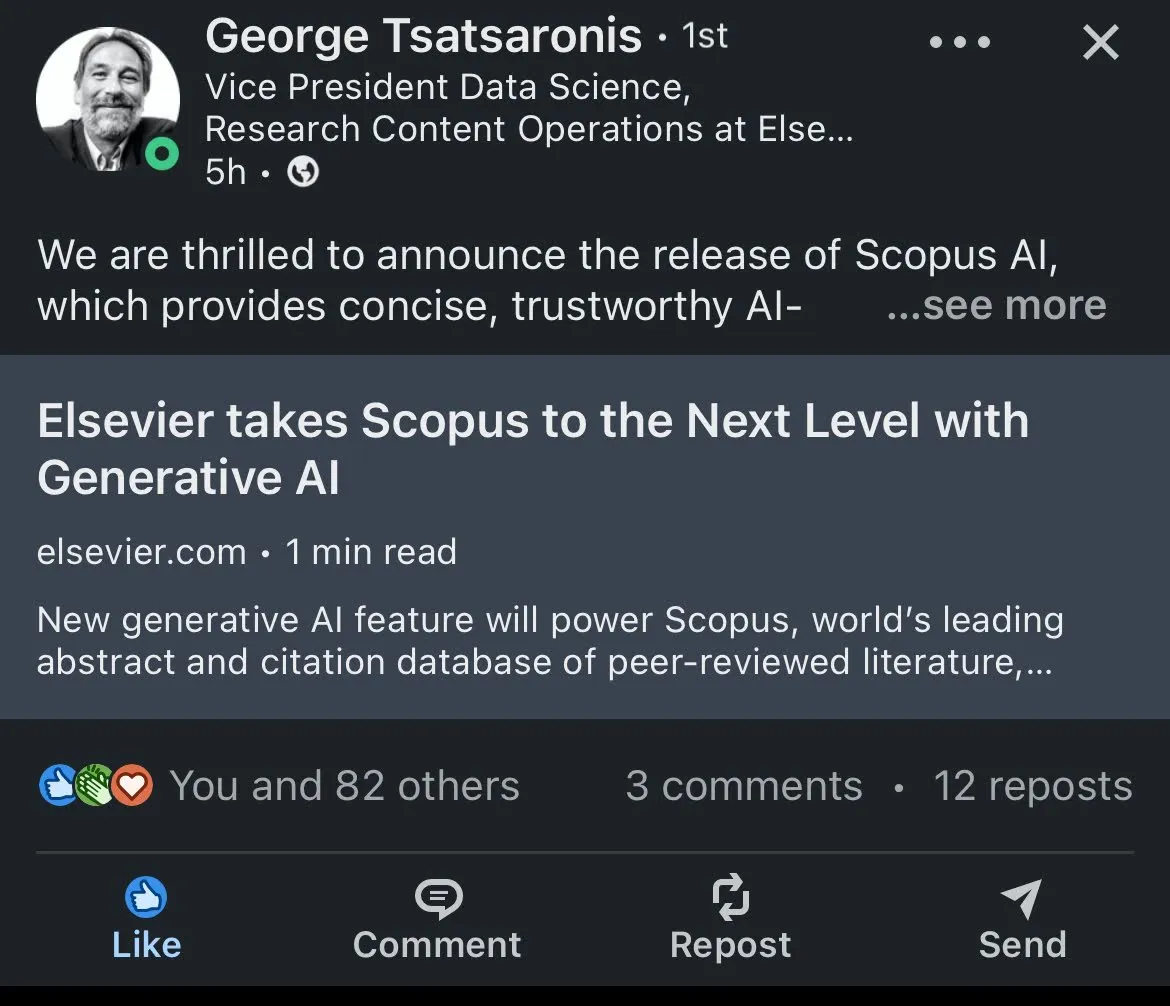
Launch day: watching it go live with a kombucha in hand
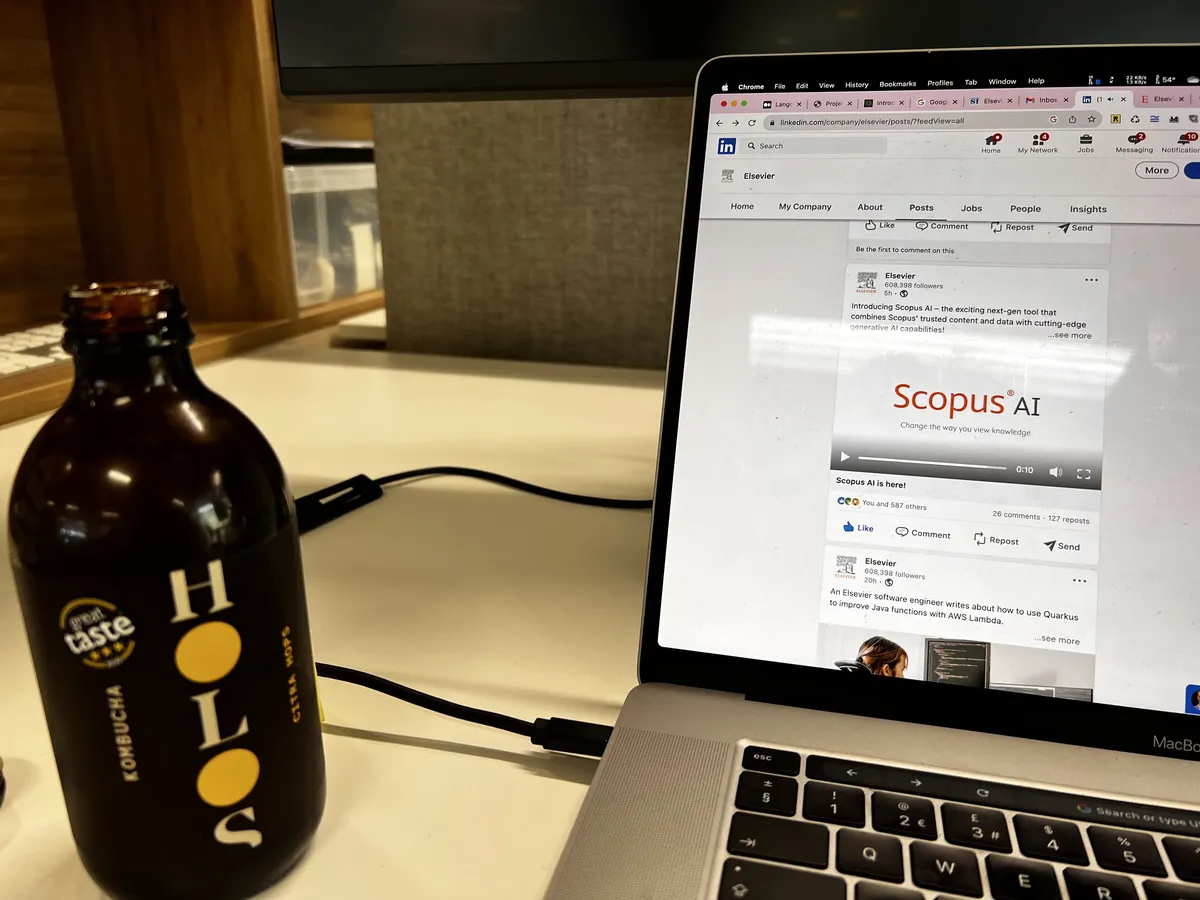
From notebook sketches to production: Scopus AI live on scopus.com

What started as a side experiment with GPT-3 became one of Elsevier's most significant product innovations. The prototype proved that generative AI could work responsibly in academic research, with proper grounding, transparent citations, and respect for the evidence. A dedicated team took that foundation and turned it into a product that researchers actually rely on. That's the outcome I'm most proud of: not the prototype itself, but the fact that it helped make the case for building something that genuinely matters.