
RAG Fusion
Open-source methodology combining retrieval-augmented generation with reciprocal rank fusion and generated queries. 900+ GitHub stars and widely adopted across the AI community.

Project Overview
My journey into retrieval techniques started at Mendeley, where I rebuilt the search experience from scratch. I was fortunate to be surrounded by mentors who guided me through the fundamentals: what precision and recall actually mean, how lexical search differs from vector search, how to think about relevance at scale. After Mendeley, I moved from user-facing product work to helping build platform search capabilities across Elsevier's product ecosystem, and that's where I started encountering more complex retrieval problems. One technique kept catching my attention: Reciprocal Rank Fusion. The idea of combining multiple ranked lists into a single, better ranking felt elegant. The problem was that it wasn't very practical unless you were already sitting down and manually pre-formulating a range of queries before firing them off. A useful technique with no scalable workflow.
Then LLMs changed the equation. During my early experiments on the Scopus AI prototype, I was thinking about retrieval in two ways. One was straightforward: generate variations of the same query to improve recall, so you weren't missing papers that used different terminology. The other was more ambitious: what if you asked a question from many different perspectives, so that when you combined the results, you'd get a genuinely comprehensive overview of a topic rather than just the papers that happened to match one phrasing?
At the time, I was quite obsessed with knowledge management systems like Obsidian, using them to collect notes and then applying search techniques to explore a topic from different angles to help with my writing. The thought kept nagging: wouldn't it be brilliant if you could apply that to everything? What if the LLM itself could write the alternative queries, which in turn would lead to a much better search experience?
Project Ramble: my personal search system, where I hooked up my Obsidian notes to vector search combined with GPT-3 in 2022
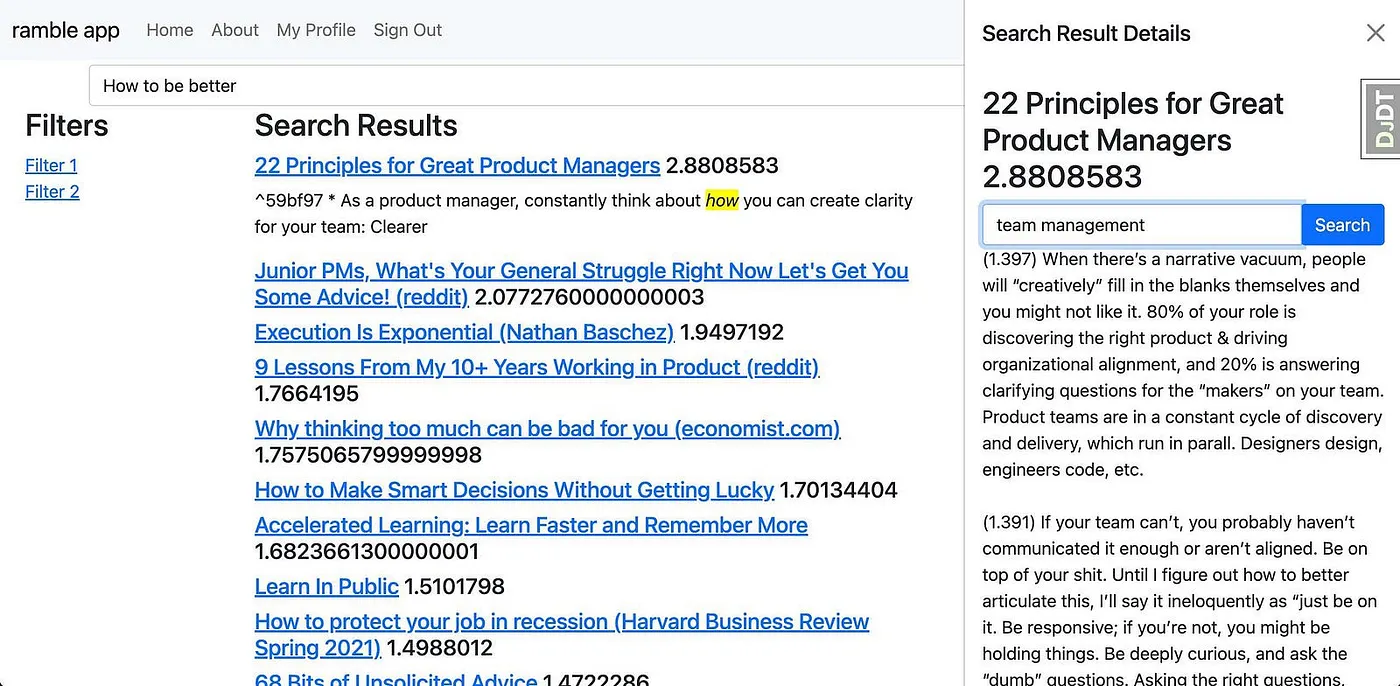
The first question I remember testing it with was "how to live a good life." It's been my go-to ever since, precisely because it's multifaceted, doesn't have a single right answer, and forces a system to think broadly. I remember seeing the results come back and feeling genuinely elated. The difference was obvious right away. I was so excited that I called up friends and close colleagues and talked endlessly about it, probably to the point of annoyance. But I could see I'd uncovered something valuable.
"How to live a good life": the first query I tested, and still my go-to for evaluating new systems
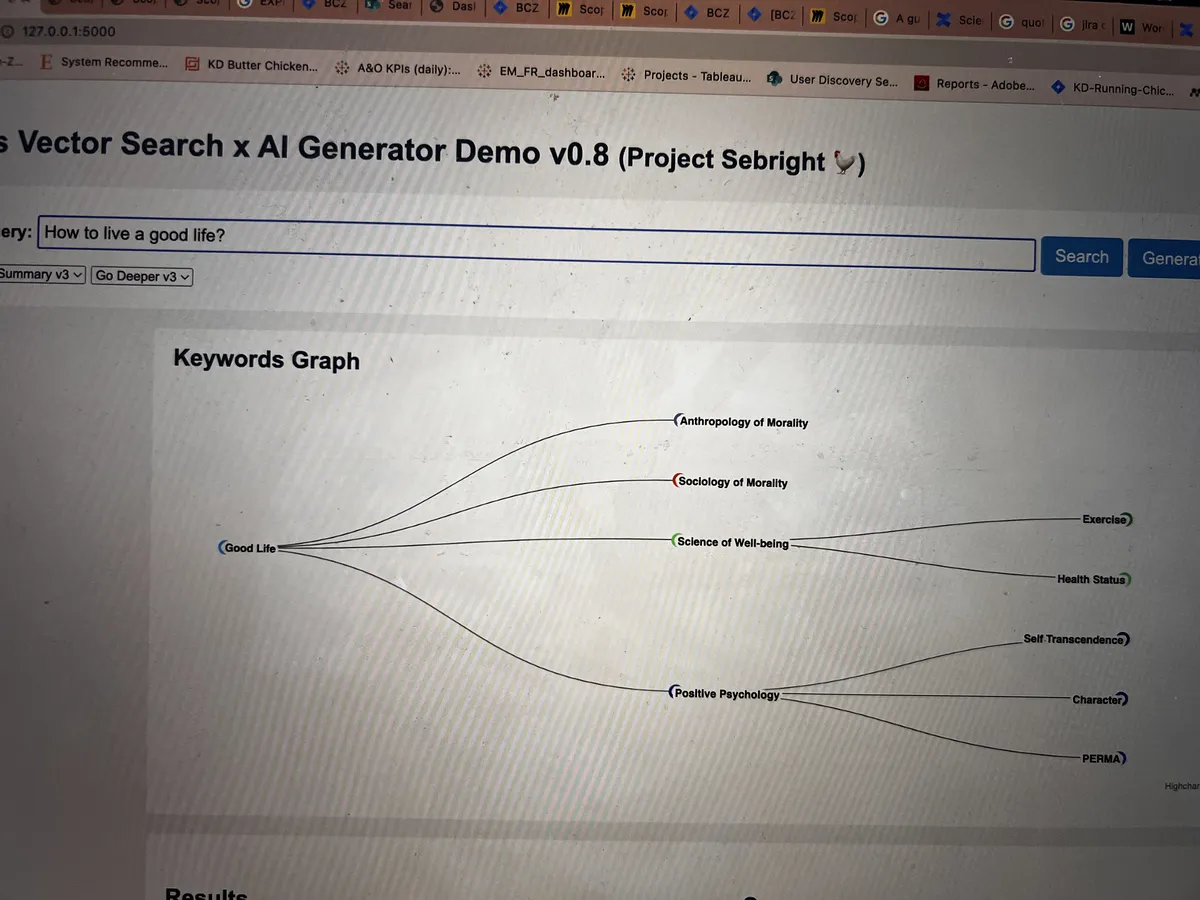
That's really what became RAG Fusion. It started as a way to improve retrieval in my own knowledge base, but it quickly became obvious the idea had much broader application. I wrote it up with a deliberately provocative title, "Forget RAG, the Future is RAG Fusion", and open-sourced the implementation. The repo has since grown to over 900 stars on GitHub. I'll admit the title was a bit much, but the technique does what it says on the tin.
The Problem with Standard RAG
Standard RAG is brilliant at what it does: take a query, find relevant documents via vector search, and use them to ground a language model's response. But it inherits a fundamental constraint from the search step. You get one query, which means one angle, one vocabulary, one way of describing what you're after.
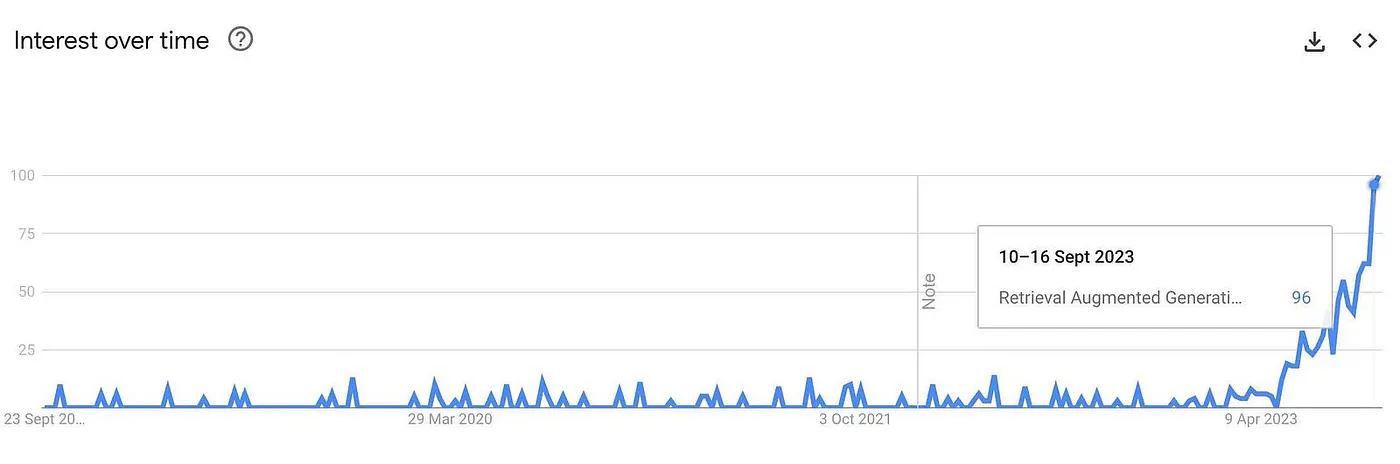
Searches for RAG skyrocketing in 2023, but the technique still had a core limitation
Researchers rarely think in single queries. Someone investigating the relationship between gut microbiota and depression might also be interested in papers about the gut-brain axis, serotonin production in the intestinal tract, or probiotic interventions for mood disorders. These are all facets of the same question, but a single vector search will only find documents close to whichever phrasing the user happened to type first. The other 90% of potentially transformative work stays buried.
The issue isn't that vector search is bad. It's that human questions are multidimensional, and a single retrieval pass only captures one dimension. What I wanted was a system that could think about the question from several angles before deciding what was relevant.
How It Works
Multi-Query Generation
An LLM takes the original query and generates multiple reformulations, each capturing a different angle or vocabulary for the same underlying question.
- •Generates 4+ alternative queries from different perspectives
- •Diverse prompt variant explicitly requests different angles, synonyms, and varied specificity
- •Casts a wider net across the document space than any single query could
Parallel Retrieval
Each generated query runs independently against the vector store, producing separate ranked result lists. The Hybrid variant also runs BM25 keyword search alongside vector search for each query.
- •Vector search via ChromaDB embeddings for semantic matching
- •Optional BM25 keyword search for exact term matching (the "free lunch")
- •Cross-disciplinary discovery: finds relevant work across fields the user might not have considered
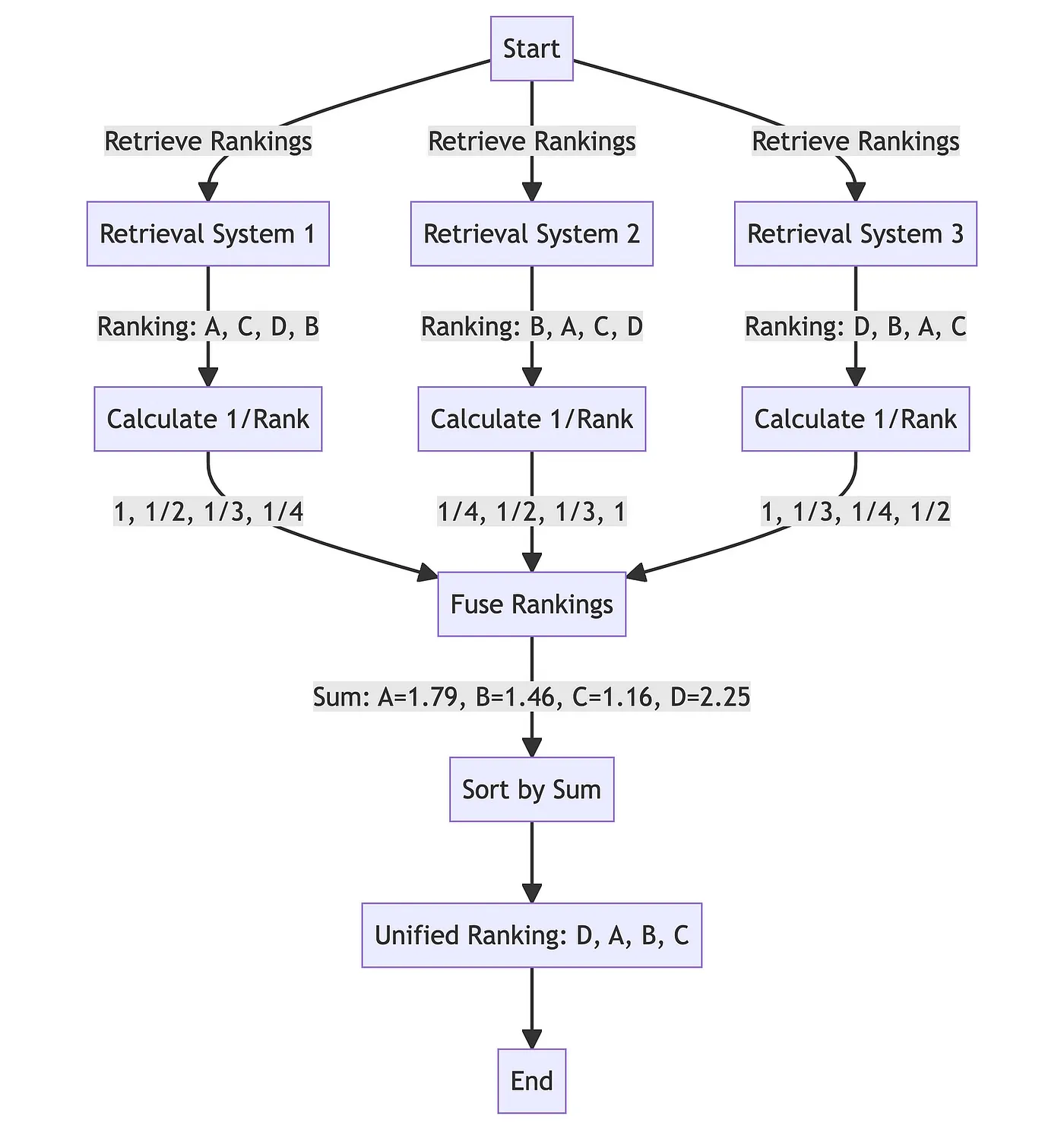
Reciprocal Rank Fusion
All ranked results are combined using Reciprocal Rank Fusion, a technique developed by Cormack, Clarke, and Büttcher at the University of Waterloo and Google (SIGIR 2009). RRF boosts documents that appear consistently well across multiple query perspectives. In their words, it "yields results better than any individual system, and better results than standard reranking methods." Documents that are only relevant to one framing get naturally deprioritised.
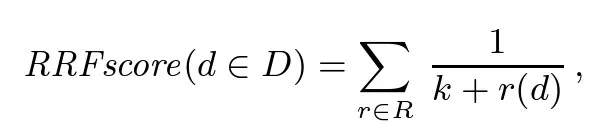
- •Produces a final re-ranked list prioritising consistently relevant documents
- •No training required: works as a drop-in enhancement to any existing RAG pipeline
- •Optionally synthesised into a natural language answer via LLM
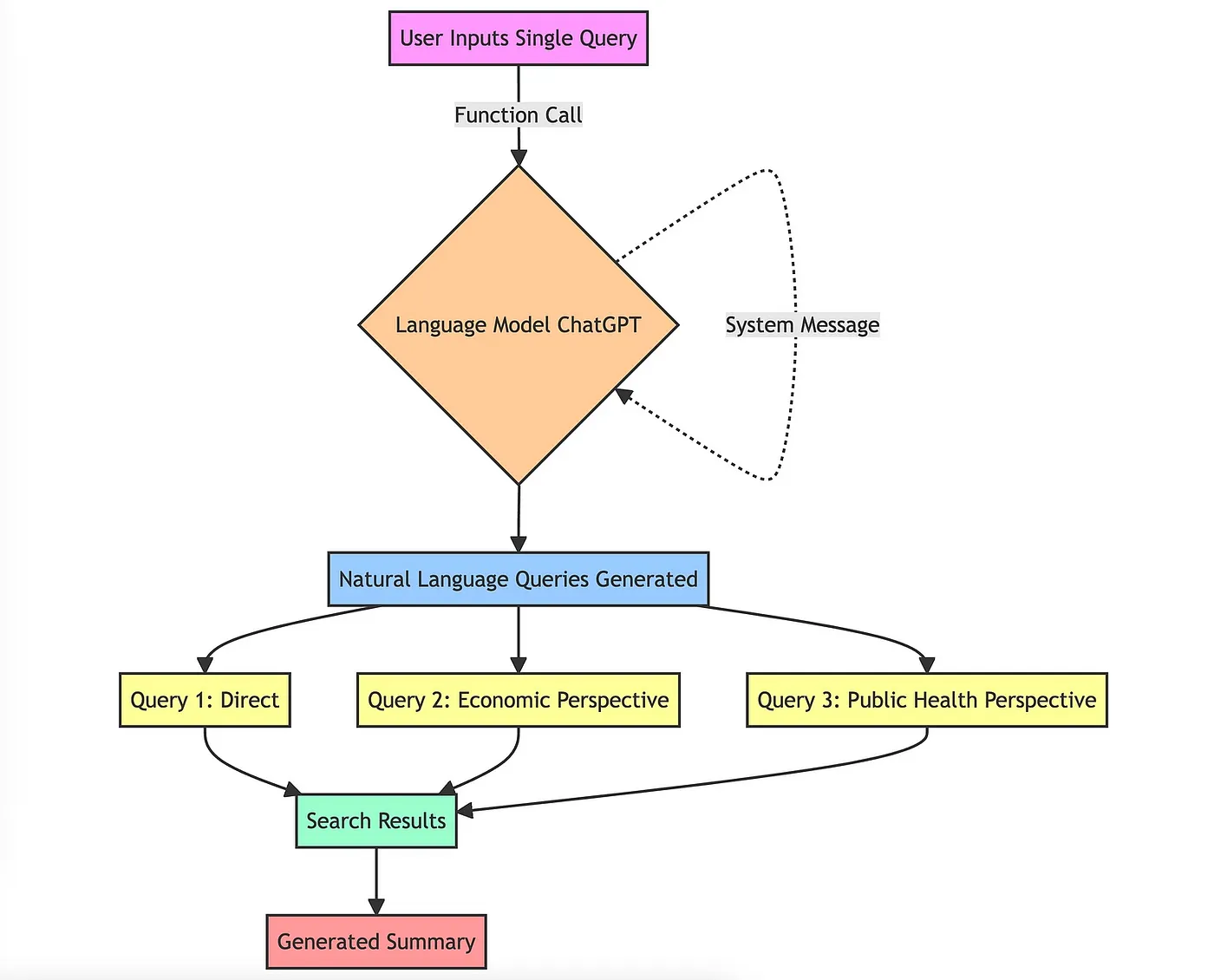
The Full Pipeline
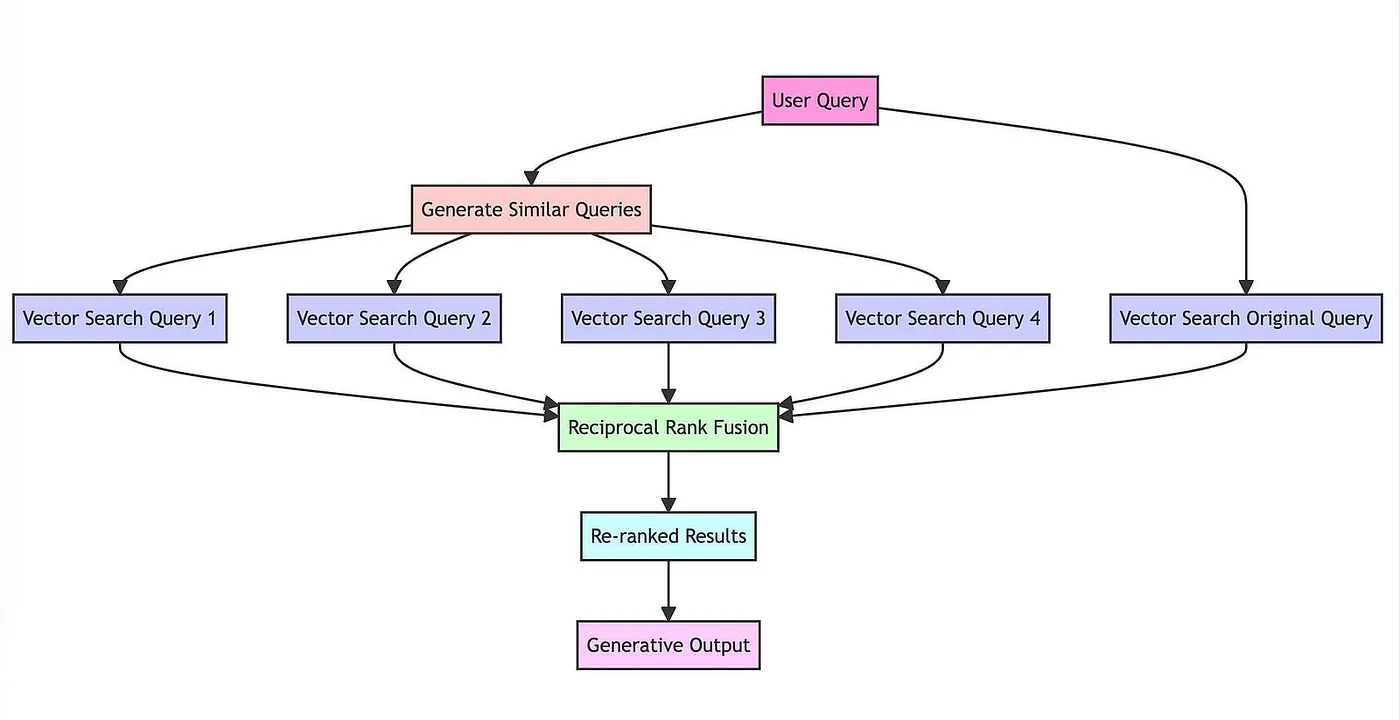
The RAG Fusion pipeline: one question in, multiple perspectives out, re-ranked results back
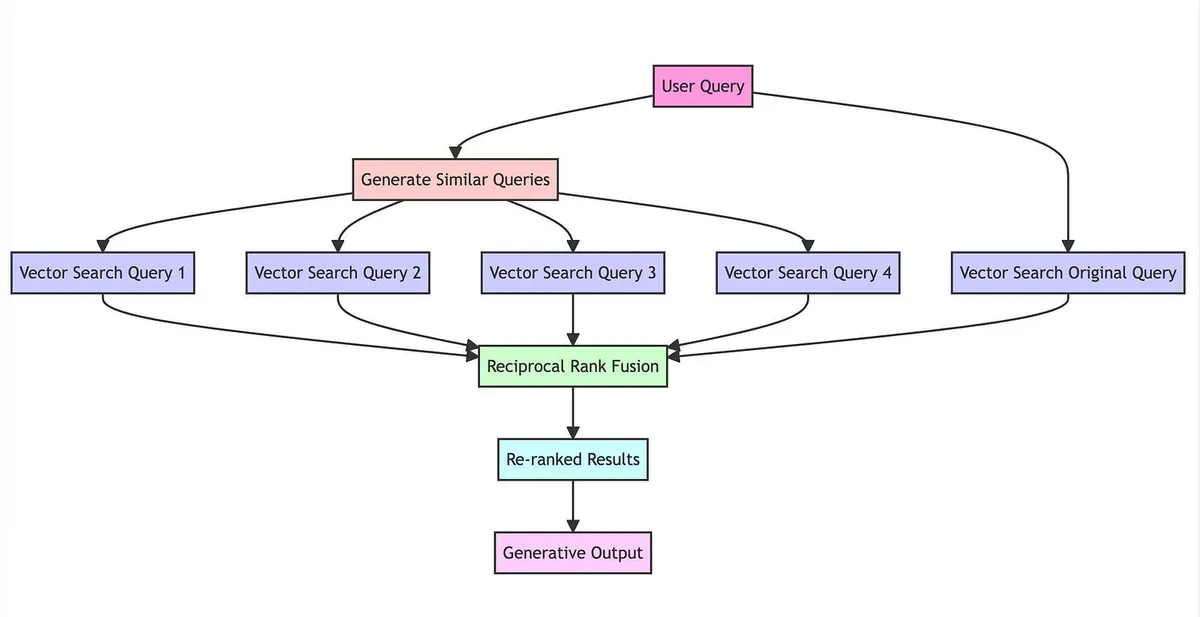
The mechanism diagram above shows how RAG Fusion's pipeline connects together. What made this approach click for me was realising that the individual components aren't new. Multi-query generation, vector search, and rank fusion are all established techniques. The contribution is in how they combine: the LLM handles the creative work of reframing the question, vector search handles retrieval at scale, and RRF handles the aggregation without needing any training data or parameter tuning.
The RAG Fusion mechanism in detail
How RRF re-ranks results by positional scoring
Evaluation Results
The repo now includes a quantitative evaluation harness using the NFCorpus dataset from the BEIR benchmark: 3,633 medical and nutrition documents with 323 test queries and graded relevance judgements. Six retrieval methods are compared, from basic BM25 keyword search through to the full Hybrid+Diverse pipeline.
Hybrid+Diverse vs single-query vector search baseline (50 queries, seed=42)
Three things stood out from the evaluation. First, hybrid search is essentially a free lunch: fusing BM25 and vector results via RRF costs nothing extra and consistently improves ranking quality, especially MRR. Second, the diverse prompt outperforms standard RAG Fusion by forcing the model to explore genuinely different angles rather than generating semantically close variations. Third, the two techniques complement each other cleanly through RRF, producing the strongest results across every metric.
Impact
Open Source Adoption
900+ GitHub stars and 110+ forks. Referenced in production systems, research papers, and conference talks across the AI community.
Production Impact
Core component of the Scopus AI prototype, which became a research platform used by millions of researchers worldwide.
Multiple Patents
The retrieval techniques developed during this work are covered by multiple patent applications at Elsevier.
Viral Article
"Forget RAG, the Future is RAG Fusion" became one of the most widely shared articles on retrieval-augmented generation, reaching audiences well beyond the AI research community.
What surprised me most was the speed and breadth of adoption. It started with posts on LinkedIn and X, then people began writing academic papers about it. One researcher from South America even asked if I'd be willing to help integrate it into drone technology for warfare, which was certainly not an application I'd anticipated when writing about search relevance. The GitHub stars kept climbing, forks multiplied, and people started publishing their own articles explaining and extending the technique. It felt like I'd finally made something that had driven real impact, and on a topic I genuinely cared about. That's exactly the reason I wanted to be in the technology space.
Where It Stands Today
I still think RAG Fusion is a solid technique, and the evaluation results back that up. But the field moves quickly, and there are alternatives emerging. The one I've come across that sometimes performs a bit better is having the AI generate an answer first and then working backwards from there to find supporting evidence. The trade-off is that approach inherits all the biases and knowledge limitations of the language model itself.
In medicine, there's a name for this failure mode: anchoring bias. A doctor latches onto the first diagnosis and then unconsciously filters all subsequent evidence through that lens. The generate-answer-first approach is essentially anchoring bias as a retrieval strategy. It can look impressive on benchmarks, but it will only ever find evidence for what the model already believes.
What RAG Fusion does differently is work from first principles. You're building knowledge from the ground up rather than starting from what the model already thinks it knows. I think that matters, especially when you're trying to explore a space where no good answer exists yet, or where you need to discover things the model hasn't been trained on. And the evaluation shows it performs even better when you combine different search techniques together, vector and lexical, through RRF. That complementarity is the real strength.
Try It Yourself
RAG Fusion is fully open source and MIT licensed. The evaluation harness lets you benchmark different retrieval strategies on a real dataset with a single command.