

Our retrieval systems run on a tight, tidy loop: ask, retrieve, confirm, repeat. Everything outside the circle, the books, the contradictions, the questions nobody asked, is noise the system is built to suppress. The compass is the thing the loop can't give you.
What working on Mendeley search taught me
In 2013, early in my pivot from medicine into technology, I was running product on an early version of Mendeley Search, the discovery feature inside Mendeley, Elsevier's newly acquired reference manager. Mendeley stored and organised the papers researchers had already collected; Search was where they went to find the next one. My team built it the way everyone builds search, optimise for relevance (much the same logic that drives today's RAG systems, and increasingly the Karpathy-style wiki knowledge layers built on top of them), measure satisfaction, ship the version where the numbers look best. The numbers did look good. Researchers came in, found what they'd asked for, and told us in surveys that the results were excellent. By the metrics we'd agreed to track, the product was a success.
But people weren't coming back. The short-term signal was strong, the long-term signal was flat. In the user interviews I ran, the answer was consistent:
"It's a good search. It helps me find what I asked for. It doesn't help me when I'm exploring."
One researcher described the experience as transactional. They were being shown the same prominent papers that every other tool was showing, the canonical citations on whatever topic they'd typed in. The tool was good at confirming what they already knew, and that was about all it was good at.
So I pushed for a counter-intuitive change. Instead of ranking purely on citation count and keyword match, we added a factor for delta change in readership, papers whose reading frequency was accelerating, not just papers that were already prominent. Up-and-coming research started surfacing alongside the established canon. Some users hated it. Satisfaction dropped, and complaints came in from researchers who expected to see familiar names and didn't, or who distrusted unknown authors they'd never encountered.
Then a strange thing happened in the A/B tests. Session length went up, weekly return rates rose, and monthly active users climbed. The metric we'd been optimising for got worse, and almost everything else got better. The friction we'd added to the experience was producing more productive sessions for researchers overall, more papers engaged with, more follow-through between sessions, more time spent reading work they wouldn't have otherwise encountered. The product had stopped being a confirmation tool and started being a discovery tool. I'd partially addressed the problem of discovery itself, the known and unknown unknowns, the papers a researcher knew to look for and the ones they had no reason to suspect existed at all.
This is Goodhart's Law in miniature: when a measure becomes a target, it ceases to be a good measure. Relevance was the target. Optimising for it had trained us, and our users, to mistake confirmation for value. Dialling back the target was what let the actual value emerge. The Mendeley experience pushed me toward evaluation frameworks like TARS, target users, active users, retention, and satisfaction, held in balance, because no single metric, pursued in isolation, can tell you whether a product is actually working. I filed that lesson away, and I've been re-learning it ever since, because what's bothering me about where we're all heading, more than a decade later, is a version of it, scaled up.
Every retrieval system, every search engine and AI assistant, every research platform we build, is optimised for relevance. Give the user what they asked for, as fast and accurately as possible that they don't even think about it. Higher relevance scores, higher satisfaction ratings, better benchmarks. By every metric we track, our systems are getting better.
But I've come to think we're measuring the wrong thing. A system that optimises for relevance gets better and better at giving users what they want, which trains those users to expect confirmation, which makes them worse at wanting what they need. The system shapes the user, who then demands more of the same system. I've started calling this the relevance trap, and the hardest part of it is this: it's not just that our systems are optimised for confirmation. It's that years of confirmation-optimised systems have trained a generation of users who now experience challenge as a product defect.
(A note on naming: Julian Fleck recently published a piece under the same title. He frames the problem as missing divergence primitives in retrieval architecture, an answer at the system level. My interest is one layer up: not what retrieval architectures lack, but what they train their users to become. Parallel diagnoses, different prescriptions.)
The building that wasn't optimised for anything
In 1943, MIT threw up a temporary plywood building to house its wartime Radiation Laboratory. Building 20 was ugly, leaky, and supposed to last six months. It lasted fifty-five years, and in that time it produced radar, the commercial atomic clock, Bose speakers, Noam Chomsky's revolution in linguistics, early hacker culture, one of the first video games, and nine Nobel Prize winners.

Building 20 (foreground), built in 1943 as a temporary facility for the Radiation Laboratory, demolished in 1998. Polaroid's headquarters sits in the background. Photo: MIT Museum, via Wikimedia Commons, CC BY 3.0.
{kind=link}
Nobody designed it to do any of that. The building worked because it was a mess. Twenty disciplines crammed into a sprawling horizontal labyrinth where the rooms were so haphazardly numbered that even longtime residents got lost in the hallways. As the electrical engineer Henry Zimmerman, who worked there for years, put it:
"In a vertical layout with small floors, there is less research variety on each floor. Chance meetings in an elevator tend to terminate in the lobby, whereas chance meetings in a corridor tended to lead to technical discussions."
The urban theorist Jane Jacobs had a term for this: knowledge spillovers. Ideas crossing disciplines by accident, through the simple architectural fact that people from different fields kept bumping into each other. Building 20 wasn't optimised for anything, which is precisely why everything became possible within it. It wasn't productive despite its friction, it was productive because of it.
I've been thinking about Building 20 because I think we are collectively building the opposite of it. Not in physical architecture, but in information architecture. Our retrieval systems are not messy, horizontal, or serendipitous. They're optimised and efficient. And buried in that optimisation is a philosophical position about how knowledge should work that almost nobody examines.
The doctor in the machine
I trained as a doctor before I pivoted to technology. I left medicine behind, stopped thinking of myself as a doctor, stopped drawing on that vocabulary, built a new professional identity in product management and search. A clean break, or so I thought.
But medical school teaches you a particular way of reasoning under uncertainty, and it turns out that way of reasoning doesn't disappear just because you stop wearing a stethoscope. In medicine, you don't start with the diagnosis. You start with the symptoms. You gather evidence, run tests, construct a differential, a ranked list of plausible explanations, and you let the picture emerge. The entire methodology is built around a single anxiety: what if we're wrong about what we think we already know?
There's a name for the failure mode. Anchoring bias. A patient walks in, mentions chest pain, and the doctor's brain latches onto "heart attack" before the examination has even started. Everything that follows gets filtered through that initial hypothesis. Confirmatory tests get ordered. Contradictory signals get downplayed. The diagnosis was made in the first thirty seconds; the next thirty minutes are theatre.
Studies on clinical reasoning have found that the best defence against anchoring isn't intelligence or experience, it's knowledge of what the discriminating features of competing diagnoses actually look like. The antidote to premature certainty is structured awareness of what you don't yet know.
A few years ago I built a retrieval system called RAG Fusion. The core insight was that a single query is a bottleneck, people are bad at articulating what they actually need. So RAG Fusion generates multiple query variations from different perspectives, retrieves evidence for all of them, and reranks everything before synthesising an answer. It fans out before it narrows down.
I didn't realise what I'd done until someone recently asked where the instinct came from. RAG Fusion is differential diagnosis for information retrieval. Gather perspectives first. Widen the evidence space before narrowing it. Let the evidence shape the answer rather than the other way around. I was encoding a medical epistemology into every search product I built, the entire time, without realising it.
Every architect does this. They just don't know they're doing it.
Two epistemologies and a loop
The competing approach to RAG Fusion, sometimes called HyDE, sometimes just "generate-answer-first", flips the epistemology entirely. You get the language model to write a hypothetical answer first, then use that answer as the search query. It's anchoring bias as a retrieval strategy: produce a hypothesis and go looking for confirmation. When the hypothesis is good, it looks brilliant, like the confident doctor who happens to nail the diagnosis in thirty seconds. When it's wrong, the failure is invisible. The system never encounters the evidence it filtered out.
That's not to say HyDE is always wrong. When you already know what a good outcome looks like, when the shape of the answer is known, and the task is just finding its best instance, generating a hypothetical answer first is a reasonable shortcut. It can also work as a seeding strategy, where an LLM generates several competing hypothetical answers and the retrieval system searches against each of them, which is really RAG Fusion with an LLM step in front of it. Where HyDE falls down is when the shape of the answer is itself the question, when you're not sure what kind of thing you're looking for, and committing prematurely to a hypothetical answer locks out the categories of evidence that would have told you.
Recent benchmarks tell a more complicated story than either camp admits, on factual and domain-specific retrieval, the generate-answer-first approach actually increases hallucination rates and adds significant latency, precisely because the generated hypothesis can drift from the actual corpus. But it doesn't really matter which approach benchmarks better, because the benchmarks themselves are measuring the wrong thing. They measure relevance, how well the system gives you what you asked for, but not whether the right question was asked.
And now there's a third approach that makes the epistemology even harder to see. Agentic AI systems, the kind that can search, read what they find, revise their understanding, and search again, iterate their way to answers. They use tools as crude as keyword matching and grep. The sophistication isn't in the retrieval mechanism; it's in the loop.
This looks like the most epistemologically honest approach of all. It resembles how a person actually researches something. But the loop itself is neutral. What matters is what steers it. An agentic system that iterates toward confirming its initial framing is just anchoring with more steps. One that genuinely revises its search based on what it finds is closer to differential diagnosis. Both systems search multiple times, both return comprehensive-looking results, and you can't tell which is which by looking at the output.
Anthropic's Claude Code recently dropped vector-based RAG in favour of agentic search, grep, file reads, pattern matching in loops. Their reasoning was pragmatic: vectors kept returning "slightly off-target information" while grep was precise, fresh, and private. For code search, that's the right choice. A developer searching for a function definition genuinely needs the exact match, not a surprising connection to a different module.
But academic search or any search requiring knowledge traversal, the domain I work in, is the opposite. A researcher who only finds exactly what they searched for has, in a meaningful sense, failed. The whole point of research is to encounter something you didn't know you needed. The same architectural choice that's correct for code is potentially catastrophic for knowledge work, and the industry debate doesn't distinguish between these because it's arguing about performance, not epistemology. Nobody is asking what kind of thinking each architecture enables. They're asking which one is faster.
Why this is so hard to escape
There's a reason the relevance trap is so persistent, and it goes deeper than bad product decisions. The brain is, somewhat humblingly, designed for it.
Predictive processing theory holds that the brain doesn't passively receive sensory data. It generates predictions about what it expects to perceive, then checks incoming signals against those predictions. Karl Friston, the UCL neuroscientist whose free energy principle underpins modern predictive-processing theory, puts it bluntly: "Trying to make sense of data without a generative model is doomed to failure." Two populations of neurons work in concert: one encoding the current best guess, another flagging prediction errors.
This is energetically efficient, the brain is the most energy-intensive organ in the body, and prediction saves energy by suppressing expected signals. It's a generate-answer-first architecture running on biological hardware. This isn't just theory, either, Cortical Labs recently trained human brain cells on a chip to play Doom using Friston's free energy principle as the learning mechanism. The cells learned by minimising surprise, not through reward. Predictive processing on a literal dish.
The implication is uncomfortable, and I think the honest thing is to sit with it rather than explain it away. Bottom-up reasoning, the kind medical training drills into you, the kind RAG Fusion tries to engineer, is the unnatural act. Our brains are hypothesis machines. Evidence-first thinking has to be imposed from the outside, through training, process, and tools.
In optimisation theory, there's a precise term for where this leaves us. It's called a local maximum, the top of a hill that isn't the top of the mountain. When you're standing on a local maximum, every small step you could take looks like it goes downhill. Everything confirms you're at the peak. The only way to reach a higher one is to accept temporarily worse results, to go downhill on purpose, which feels like the system is broken.
The relevance trap is a local maximum problem. The user is on a peak. The system keeps confirming they're at the top. Higher relevance, higher satisfaction, all metrics green. But the mountain, the genuinely novel insight, the cross-disciplinary collision, the thing they didn't know they needed, is on the other side of a valley that the system has been carefully designed to prevent them from entering.
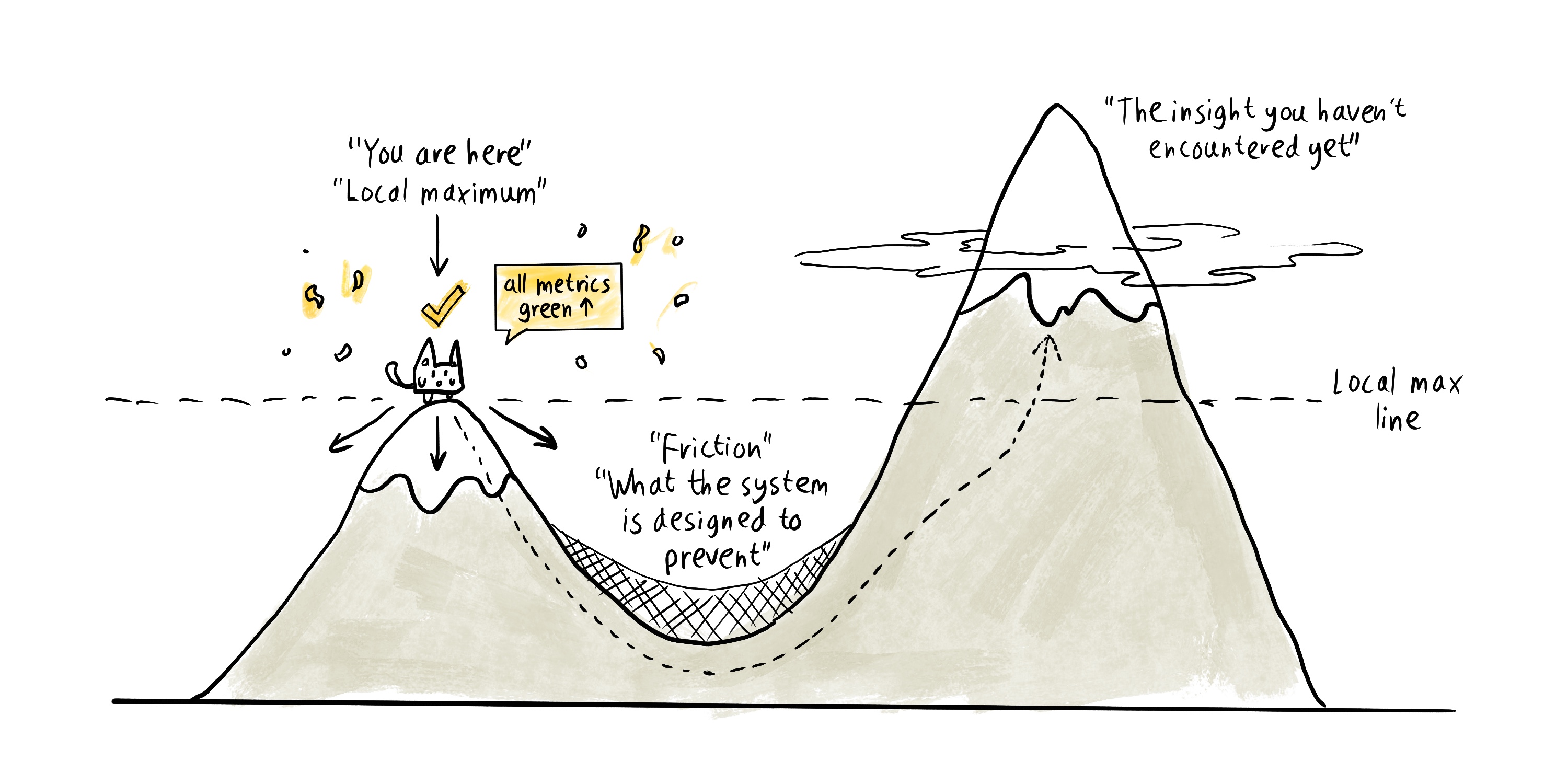
The local maximum problem: every metric green, every dashboard lit, and still nowhere near the peak that matters. The valley between is the part the system is built to smooth away.
Philosopher Erich Fromm had a useful framework for this. He distinguished between negative freedom, freedom from constraints, and positive freedom, freedom to act meaningfully. A relevance-optimised system provides negative freedom beautifully: it removes the friction of bad results, irrelevant noise, the work of sifting. But it doesn't provide positive freedom, the capacity to discover, to be surprised, to encounter what you didn't know you needed. As Fromm put it:
"You can cut off all the chains that are holding you down but if you have no where you want to go... then what's the point?"
This has consequences beyond individual searches. I've written before about innovation slowing down, genuinely novel breakthroughs have become rarer despite our extraordinary computational tools. The usual explanations focus on the burden of knowledge or institutional incentives. But I think there's another mechanism: our tools are deciding which intellectual collisions are even possible. A philosopher searching for ethics gets philosophy back. A biologist searching for gene expression gets biology. The system optimises for coherence within the user's vocabulary, which means it optimises against the cross-disciplinary collision that might produce something genuinely new. Building 20 worked because it had no such filter, a linguist didn't have to search for "nuclear physics" to encounter nuclear physicists. As the serendipity researcher Christian Busch argues, you are only open to innovation when you are open to conflict, when an idea might not work. A relevance-optimised system eliminates conflict and surprise, removes the productive discomfort of encountering something that doesn't fit your model.
I should say this pattern has been surfacing in parallel corners of the field. Bottino and colleagues have recently argued that the ceiling on organisational AI is epistemic fidelity, not retrieval fidelity, the system's ability to represent commitment strength, contradiction status, and organisational ignorance as computable properties, rather than merely surfacing semantically relevant content. I'd push the argument one step further. Academic search has the same ceiling, with an additional layer on top, whether the users we build these systems for have been shaped, by the retrieval environments they already inhabit, to tolerate encountering the system's uncertainty at all. It isn't only that our tools fail to model their own ignorance, it's that their users are increasingly disinclined to notice when they should.
I've been writing around this idea for years, in the RAG Fusion article, in the piece on ChatGPT and academic search, in essays about design encoding assumptions about control, without naming the pattern. I think the pattern is this: the tools we build to find knowledge encode assumptions about how knowledge should be constructed, and those assumptions compound over time into the intellectual environment their users inhabit.
What I've been trying to do about it
I don't think the answer is to ban top-down approaches. The brain anchors for good reasons, predictive processing isn't a flaw, it's how biological intelligence manages an overwhelmingly complex world. What matters is whether anchoring goes uncorrected. And here I've had to revise what I once believed.
For a long time I wrote and spoke as if the correction for anchoring was awareness, the doctor who knows they're anchoring can correct for it, the one who doesn't can't. The clinical literature is more uncomfortable than that. Wilson and colleagues showed in 1996 that participants explicitly forewarned about anchoring, and asked to correct for it, could not. Pronin's bias blind spot work is sharper still: people who introspect harder about their own biases detect more of them in others and less in themselves, because anchoring operates below the waterline of conscious reasoning. Which means the self-aware doctor is relying on the worst available detector.
What actually works, when anything works, is architectural. Consider-the-opposite protocols that force the diagnostician to list reasons the leading hypothesis might be wrong. Checklists that require the generation of alternatives before a decision closes. Structured second opinions. Higher domain knowledge, which protects better than vigilance. The common thread is that none of them rely on the biased reasoner to notice their own bias. They externalise the correction into the process.
LeapSpace, the research AI product I work on now, was built around what I now understand as a forcing-function bet. Trust cards don't just display an alignment score; they surface alternative perspectives the user didn't ask for, by design. Deep research mode uses an agentic loop, but each agent in the swarm is tasked with exploring variations of the query from different angles rather than confirming the original framing. Both are friction by design, the same counter-intuitive bet Mendeley made with delta-readership, now scaled up from ranking to synthesis. If RAG Fusion was me unconsciously encoding a medical epistemology into retrieval, this was the conscious version: differential diagnosis as a design constraint, applied deliberately because I'd finally recognised what I'd been doing all along.
The honest result is mixed. In our internal research, a chemistry researcher told us:
"ChatGPT gave me fifty references in five minutes, but I spent the next three hours discovering half were fabricated. Now I'd rather do it manually than risk citing non-existent papers."
That's the failure mode confirmation-first retrieval produces at scale. Not quiet over-trust, but a sudden lurch back to doing things manually, which is arguably worse, the user who's been burned once has no reason to extend trust to the next epistemic aid either.
I should be honest about my own position here. I'm constitutionally the kind of person who builds friction into their own tools. I wrote Python scripts to organise my highlights before Readwise existed, because the manual version was too smooth to learn from. So when I see users route around epistemic friction I've deliberately designed, my instinct is bewilderment, and that instinct is, I think, the bias I've had to correct in myself. The users who route around aren't failing to understand the friction. They've been shaped, by years of satisfaction-first systems, into treating any friction as a product defect. The people who most need differential-diagnosis retrieval are the ones our industry has trained hardest to reject it.
What this looks like when it works
I've been running a small version of this for over a year. My own knowledge store lives in Obsidian, a note-taking app that treats your notes as a linked network rather than a filing cabinet (basically a super fancy diary). Mine holds a few thousand notes, many with bidirectional links, tagged and organised by a taxonomy I trust because I built it. When I ask it a complex question, the system doesn't try to return an answer. It runs a series of searches, inspects what's direct, identifies what's adjacent, follows links into the notes it finds, searches externally when the internal evidence is thin, and builds the picture in stages. Each stage can be inspected, and each link in the chain is a place I can stop and redirect.
Andrej Karpathy recently published a version of this same pattern, a personal wiki queried by an LLM that has to read and synthesise rather than guess. It is, I think, the direction the best retrieval architectures are already moving: away from a single-shot search over a vector index, toward staged agentic traversal of a curated knowledge graph. The word curated is doing work there. What makes these systems better isn't the retrieval mechanism so much as the fact that the corpus has been shaped, by a person, into something that rewards multi-step reasoning rather than flat lookup.
What I care about here is what this architecture does to the user, specifically, to me. I can't ask a question without engaging with what I already know. Gaps in my own map become visible rather than buried. I'm forced to take responsibility for what's in the system, because anything I accept uncritically becomes what the agent reasons from next time. And the line of logic from question to answer is something I can inspect and reuse, not a black-box answer but a reusable map of how I arrived. The system's output stops being a substitute for my thinking and becomes a scaffold my thinking has to run along.
This is, I suspect, the closest thing to a positive prescription I have. Not "use Obsidian", the tool is incidental. The pattern is: construct knowledge in stages, expose the gaps, keep the logic of arrival visible, take responsibility for the primitives, and design the system so the user has to engage with the structure rather than bypass it. Every retrieval product can be measured against this. Most, at the moment, don't come close.
Building 20 in reverse
Building 20 was an accident. MIT didn't mean to produce radar and linguistics and nine Nobel laureates in a plywood shed; the shed was supposed to last six months and then be forgotten. What it showed, in retrospect, is that the most productive intellectual environments are often the ones that feel least like they're working, the ones with enough friction and mess and wrong turns that you end up somewhere you never planned to go.
The difference now is that we know. We're no longer building Building 20 by accident, any more than we're accidentally building plywood sheds. Every retrieval architecture, knowledge system or leadership avatar is the output of deliberate design choices about what kind of thinking the tool rewards. The real question isn't whether we can build the intentional version of Building 20, it's whether we might be accidentally building its inverse. A system that grinds down the friction, the wrong turns, the accidental collisions that made it work in the first place, one efficiency gain at a time, and puts a smooth confirming mirror where the unplanned corridor used to be.
I think we might be.
When the search target is a person
So far I've been describing retrieval over documents. The same architecture is now being pointed at people. Mark Zuckerberg is reportedly having Meta build an AI version of himself, trained on his voice, image, mannerisms and years of public statements, to hold one-on-one conversations with all 75,000 Meta employees. Offer feedback, handle promotion requests, be personally present to every employee on the same day if needed. Several founders I know have started describing, only half-jokingly, the LLM-queryable document of their leadership style that would let more decisions route around them. The corpus is no longer a knowledge base. It's a person's past thinking.
The immediate objections to this are by now familiar. There's the economic one, if the avatar runs the company's internal interactions, what is the CEO for? There's the relational, "if I send you an email, and an AI responds, I do not want to work with you", as one commenter put it. And there's the accountability objection, an avatar can't commit to anything it says, which makes its decisions orphaned from the moment they're made. These are good objections, and they're all true. I think there's a deeper one upstream of all of them.
This inherits every flaw I've described and adds a new one. An avatar trained on someone's past patterns is, by construction, a relevance-optimised approximation, it returns what the person would have said, calibrated on the past. It's HyDE for human judgement. Except now the failure mode is worse than fabricating a citation. It's that the represented person no longer has to change their mind, because change of mind requires real encounter with new context, the specific sentence that lands differently today, the disagreement that shifts what you think by Tuesday. An avatar is a machine for performing last week's version of a person indefinitely.
There's a quieter consequence beyond the individual. "Nobody ever got fired for hiring IBM" becomes "nobody ever got fired for checking with the Mark-avatar." An always-available representation of leadership isn't a convenience so much as a compliance structure, whether or not anyone intended it that way. Decisions get pre-litigated against a surface that can't be argued with because it isn't really there. The same retrieval logic that trains users to experience challenge as a product defect now trains organisations to experience disagreement as insubordination against the archived self of a leader who isn't even in the room.
The meta-layer makes this more unstable, not less. Every avatar is rendered by whichever frontier model happens to be live at that moment. You're not consulting your CEO, you're consulting a statistical reconstruction of your CEO, filtered through whatever RLHF tilt got deployed last month. The accountability shield you thought you had is mounted on a foundation that rotates under you silently, every few weeks.
I want to concede the steelman here. Most meetings don't require a change of mind, most decisions don't need a leader's actual attention, and an avatar scaling a founder's bandwidth so more junior people get a decision is, in many ordinary cases, a mercy. It's possible this concern is overblown. Even so, the cases that matter are the ones where real change of mind was the only thing that would've helped, and those are exactly the cases a well-calibrated avatar is architecturally least likely to produce.
The structural mistake is the same one I've been writing about throughout this piece. A system built to return the most relevant answer will, given enough time and feedback, produce a user population that treats the most relevant answer as the right one. Pointed at documents, the failure is narrowed research and flattened thinking. Pointed at people, the failure is that individuals get locked into the version of themselves the system already has.
The stakes
The long-term concern isn't that any given relevance-optimised system misleads a researcher on a given afternoon. It's the compounding effect on innovation itself. I've written before about the measurable slowdown in genuinely novel breakthroughs, the usual explanation blames the burden of knowledge or broken institutional incentives. The mechanism I'm now most worried about is quieter than either. Our tools are deciding which intellectual collisions are even possible, which disagreements get entertained, which changes of mind get a chance to happen. And at the human layer, avatars, leadership wikis, organisation-scale representations of past-selves, they're deciding which people get the chance to change in the first place.
The earlier sections of this piece argued that the relevance trap narrows what you find. The avatar extension is that it also narrows who you get to become. And because the narrowing feels like efficiency, the metrics will confirm it's working. Higher satisfaction, faster decisions, fewer meetings. All the dashboards will be green. Somewhere on the other side of the valley, the mountain continues to exist, unvisited, with no instrumentation to notice it's there.
I keep coming back to a line from E.F. Schumacher:
"Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius, and a lot of courage, to move in the opposite direction."
Building the tool that pushes back, rather than the one that gets out of the way, takes both. Don't trust the map. Trust the compass. And if your system has neither, if it only ever points you back at the peak you're already standing on, build a system with friction in the right places.
Work that inspired this article
- Friston, K. (2010). The free-energy principle: a unified brain theory? Nature Reviews Neuroscience. The foundational paper behind predictive processing, why the brain is, by default, a confirmation machine, and why evidence-first reasoning has to be imposed from outside.
- Wilson, T. D., Houston, C. E., Etling, K. M. & Brekke, N. (1996). A new look at anchoring effects. Journal of Experimental Psychology: General. The landmark finding that warning people about anchoring bias doesn't stop them from anchoring, the evidence that pushed me away from "awareness" as a solution and toward architectural forcing functions.
- Pronin, E., Lin, D. & Ross, L. (2002). The bias blind spot: Perceptions of bias in self versus others. The uncomfortable finding that people who introspect harder about their own biases detect more in others and less in themselves. The self-aware doctor uses the worst available detector.
- Cormack, G., Clarke, C. & Buettcher, S. (2009). Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods. SIGIR. The technical backbone of RAG Fusion for anyone who wants to see how combining multiple rankings into one actually works.
- Gao, L. et al. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. The original HyDE paper, the generate-answer-first retrieval method discussed in Two Epistemologies as the competing approach to RAG Fusion.
- Bottino, F., Ferrero, C., Dosio, N. & Beneventano, P. (2026). Retrieval Is Not Enough: Why Organizational AI Needs Epistemic Infrastructure. The parallel academic argument at the institutional scale: organisational AI is bottlenecked by epistemic fidelity, the ability to represent commitment, contradiction, and ignorance, rather than retrieval quality.
- Fleck, J. (2025). Divergence Engines: Escaping the Relevance Trap. Medium. The parallel essay under the same title, from the system-design angle, what retrieval architectures lack, rather than what they train their users to become. Worth reading alongside this one.
- Karpathy, A. (2026). Personal Wiki / LLM retrieval gist. Recent public formulation of the curated-knowledge-graph-plus-agentic-LLM pattern. The shape a good retrieval system increasingly takes when it's done well.
- Raudaschl, A. (2023). Forget RAG, the Future is RAG-Fusion. My earlier writeup of multi-perspective retrieval, differential diagnosis encoded into a search architecture without my realising it.
- Raudaschl, A. TARS: A Product Metric Game-Changer. UX Collective. Target users, active users, retention, satisfaction, the product evaluation framework the Mendeley lesson pushed me toward. If you found the Goodhart section useful, this is where I worked the rest of the argument out.
- Schumacher, E.F. (1973). Small Is Beautiful: Economics as if People Mattered. Source of the closing line on the courage required to move in the opposite direction. Still the best book on the politics of scale and why more-and-bigger isn't always better.
- Raudaschl, A. (2022). Innovation is Slowing Down. My earlier argument that our tools are quietly constraining the cross-disciplinary collisions innovation depends on. The observation that seeded this essay.
- Raudaschl, A. (2021). Brainwashed by Design. My first attempt at the pattern this piece describes, how design choices encode assumptions about control, written before I had the vocabulary for it.
- Goodhart's Law, Charles Goodhart's 1975 original, and Marilyn Strathern's 1997 reformulation ("when a measure becomes a target, it ceases to be a good measure") which is the version most people know.
- Mendeley Search, the product the opening anecdote is about.
- MIT's Building 20, Quartz on the "magical incubator" that housed 20 disciplines and nine Nobel laureates.
- Groupthink: The brainstorming myth, New Yorker piece on Building 20 and knowledge spillovers.
- The Role of Clinical Reasoning in Diagnostic Excellence, UCSF primer on anchoring bias in medicine.
- The Anchoring Bias Reflects Rational Use of Cognitive Resources, argues anchoring is an optimal strategy given cognitive constraints.
- Assessing RAG and HyDE on 1B vs. 4B-Parameter Gemma, benchmark comparison showing HyDE's trade-offs.
- Claude Code Doesn't Index Your Codebase, how agentic grep replaced vector RAG.
- Settling the RAG Debate, analysis of the Claude Code architectural decision.
- RAG is Dead, Long Live Agentic Retrieval, LlamaIndex on agentic strategies.
- Human brain cells on a chip learned to play Doom, Cortical Labs and the free energy principle in action.
- Mark Zuckerberg is reportedly building an AI clone to replace him in meetings, Hacker News thread on the Meta avatar project.
- Let's Replace All Corporate Chiefs With AI, Timothy Noah, The New Republic, on executive redundancy.